
데이터 셀렉션 및 필터링 (p.62)
넘파이의 경우에는 [ ]연산자를 이용해서 값을 추출하거나, 슬라이싱 , 인덱싱 등을 수행했었는데, 판다스의 경우 .iloc[]이나 .loc[]를 이용하여 동일한 작업을 수행한다.
그전에 우선 판다스의 [ ]연산자와 넘파이의 [ ] 연산자의 차이를 알아보자
우선 쉽게 이해하려면 판다스에서의 [ ] 연산자는 단순하게 column을 지정할 수 있는 연산자라고만 생각하면 편하다.
예를 들어 데이터프레임에서 특정 컬럼을 추출하고자 하는데, [ ] 안에 컬럼명이 아닌 숫자등을 적게 되면 오류가 난다.
그런데 또 숫자를 적으면 무조건 오류가 나는 것이 아니라, 단일 숫자값등을 적으면 오류가 나는데,
인덱싱을 나타내는 0:2 혹은 boolean 인덱싱을 나타내는 것들은 [ ] 안에 적을 수 있다.
df[0:2]
df[df['pclass']==2]DataFrame iloc[ ] 연산자 (p.64)
판다스에서는 인덱싱 방식으로 iloc와 loc가 있는데, iloc는 위치 기반 인덱싱이고 loc는 명칭 기반 인덱싱이다.
위치 기반 인덱싱은 행과 열의 위치를 행과 열의 위치를 0을 출발점으로 하는 좌표값으로 지정하는 방식이며,
반대로 명칭기반 인덱싱은 데이터 프레임의 인덱스 값으로 행 위치를, 칼럼의 명칭으로 열 위치를 지정하는 방식이다.
우선 iloc[ ] 연산자는 행과 열의 좌표 위치에 해당하는 값으로 정수값 혹은 정수형의 슬라이싱 등만을 입력할 수 있다.
우선 아래와 같이 임의의 데이터 프레임을 생성해보자.
아래의 데이터 프레임은 인덱스도 직접 지정한 one, two, three, four로 되어있다는 것도 기억해두저,
data = {'Name': ['Chulmin', 'Eunkyung','Jinwoong','Soobeom'],
'Year': [2011, 2016, 2015, 2015],
'Gender': ['Male', 'Female', 'Male', 'Male']
}
data_df = pd.DataFrame(data, index=['one','two','three','four'])
data_df
이 때 데이터 프레임의 첫번째 행, 첫번째 열의 데이터를 iloc을 사용하여 추출하려면 좌표값처럼 사용하면 된다
data_df.iloc[0,0]
>> 'Chulmin'그러나 동일한 값인 첫번째 인덱스에 첫번째 컬럼명을 iloc에다가 적게 되면 오류가 난다.
data_df.iloc['one','Name']
>> ValueError: Location based indexing can only have [integer, integer slice (START point is INCLUDED, END point is EXCLUDED), listlike of integers, boolean array] typesiloc에서는 단순한 숫자뿐만 아니라 슬라이싱을 이용하여 여러 row와 column도 뽑을 수 있다.
단 iloc은 정확한 좌표등을 적어줘야하기 때문에 boolean방식의 인덱싱이 불가능하다.
DataFrame loc[ ] 연산자 (p.67)
loc[ ]는 명칭 기반으로 데이터를 추출한다. 따라서 아까 iloc에서 오류가 났던 index명과 column명으로 접근하는것이 loc[ ] 방식이다.
data_df.loc['one','Name']
>> 'Chulmin'다음으로 loc에서 유의해야할 점이 있는데, 본래 슬라이싱에서 start:end라고 표시하면 end이전까지를 의미한다.
즉 만약 [0:5] 하면 0,1,2,3,4의 위치한 값들이 나오는게 보통 일반적인 슬라이싱 방식의 인덱싱인데, loc의 경우는 명칭기반이기 때문에
슬라이싱을 할 떄도 숫자가 아닌 명칭이 들어가기 때문에 끝값을 포함하게 된다.
요약→ loc에서의 슬라이싱은 start:end에서 end값을 포함한다.
아래와 같이 three까지 진행했을 때 three의 row도 출력이 된다.
data_df.loc['one':"three"]
loc[ ]의 경우에는 boolean 인덱싱이 가능하다.
titanic_df.loc[titanic_df['Age'] > 60, ['Name','Age']]불린 인덱싱 (p.70)
사실 위에서 언급한 loc와 iloc같은 경우는 데이터의 row와 col의 위치를 정확히 알고있을 때 사용할 수 있기 때문에 boolean방식의 인덱싱을
실제로는 많이 사용하게 될 것이다. 이러한 boolean 인덱싱은 [ ] 안에 우리가 뽑고자 하는 데이터의 조건만 적어주면 뽑을 수 있기 때문이다.
이 boolean indexing은 [ ]안에 바로 쓸 수도 있고, loc뒤에 쓸 수도 있다.(iloc에는 아까도 말했지만 불가)
단 이 loc뒤에 쓸 때는 적용하려는 column을 알맞은 인자 위치에 적어줘야한다. 아래 두 코드는 동일한 코드이다.
df[df['Age'] > 60][['Name','Age']].head(3)
df.loc[df['Age'] > 60, ['Name','Age']].head(3)또한 조건을 쓸 때 복합조건을 사용할 수 있는데 복합조건이란, and를 의미하는 &, or을 의미하는 | , not을 의미하는 ~를 적을 수 있다.
사용법은 각 조건에 ( )를 쳐줘 구분하고, 위의 연산자를 적어주면 된다.
df[ (df['Age'] > 60) & (df['Pclass']==1) & (df['Sex']=='female')]정렬, Aggregation 함수, Groupby 적용(p.73)
DataFrame, Series의 정렬 - sort_values() (p.73)
DataFrame과 Series의 정렬을 위해서는 sort_values 메서드를 이용한다. sort_values는 by, ascending, inplace 등의 인자를 사용할 수 있다.
우선 by는 어떤 행을 기준으로 정렬 할지를 의미하고 ascending은 default는 True로 지정되어 있으며, True는 오름차순, False로 지정하면 내림차순 정렬을 한다.
마지막 inplace는 이전 drop에서 확인했듯이, 실제 df에 반영하는지 여부이다.
df.head(3)
df_soted = df.sort_values(by=['Name'])
df_soted.head(3)

이렇듯 by를 통해 Name을 기준으로 정렬했으며, ascending 인자를 따로 설정하지 않았으므로 default로 오름차순 정렬이 되어있으며 df_sorted에 값을 할당했기 때문에 inplace도 사용하지 않았다.
또한 by에는 여러가지 컬럼을 적을 수도 있다.

Aggregation 함수 적용 (p.74)
데이터프레임에서는 min(), max(), sum(), count() 와 같은 aggregation 함수의 적용을 할 수 있다.
기본적으로 column을 지정해주지 않으면 데이터프레임내에 있는 모든 컬럼에 대하여 수행한다.
groupby() 적용 (p.75)
데이터프레임에 groupby함수 안에 by인자에 컬럼을 지정하면 해당 컬럼을 기준으로 groupby를 진행한다.
groupby를 진행하면 DataFrame Groupby객체를 반환한다.
df = df.groupby(by='Pclass')
print(type(df))
>> <class 'pandas.core.groupby.generic.DataFrameGroupBy'>이렇게 groupby된 상태에서 aggregation함수들을 이용하여 다양한 통계값등을 볼 수 있다.
또한 아래와 같이 다양한 aggregation함수를 한번에 적용하여 확인할 수도 있다.
df.groupby('Pclass')['Age'].agg(['max', 'min'])
>> max min
Pclass
1 80.0 0.92
2 70.0 0.67
3 74.0 0.42위와 같이 한 컬럼에 다양한 aggregation함수를 적용하는 것 뿐만 아니라, 딕셔너리를 이용하여 다른 컬럼에 다른 aggregation 함수를 적용할 수도 있다.
df.groupby('Pclass').agg({'Age':'max', 'SibSp':'sum', 'Fare':'mean'})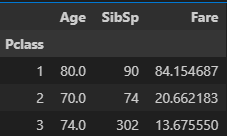
결손 데이터 처리하기 (p.77)
pandas는 결손 missing 데이터를 처리하기에 편리하다. 결손 데이터란 컬럼에 데이터가 없는 것 NULL을 의미하며, 이는 numpy의 NaN으로 표시한다.
대부분의 머신러닝 알고리즘은 이 NaN값을 처리하지 않기 때문에 사전 처리가 필요하다.
또한 이러한 Nan값은 평균, 총합 등의 함수 연산지에 자동적으로 제외된다.
이러한 NaN값을 확인하는 방법은 isna()가 있고, 이 NaN값을 채우는 방법은 fillna()가 있다.
isna()로 결손 데이터 여부 확인 (p.77)
isna()는 말 그대로 데이터가 NaN인지 알려준다.
isna()의 반환값은 True/False로 데이터프레임 전체에 적용하면 전체 데이터에 대한 true false값이 나오게된다.
이렇게 하면 한눈에 알아보기 힘들기 때문에 보통 sum()함수랑 같이 써서 nan값의 개수를 확인하기도 한다.
df.isna().head(3)
df.isna().sum()

fillna()로 결손 데이터 대체하기 (p.78)
fillna()를 이용하면 결손데이터를 다른값으로 대체할 수 있다.
단순하게 ()안에 대체하고자 하는값을 적어주면 바꿔지는데, 이 fillna()도 안에 inplace 파라미터를 넣어주냐 안넣어주냐에 따라 데이터에 직접 반영되냐 안되냐가 달라진다.
apply lambda 식으로 데이터 가공
판다스는 apply 함수에 lambda식을 결합하여 데이터를 핸들링할 수 있다.
우선 lambda는 파이썬에서 함수를 작성하는 방식 중 하나인데, 일반적인 def로 정의하는 함수가 아니라, 잠깐씩 쓰는 방식이다.
lambda
우선 입력값의 제곱값을 구해주는 함수가 있다고 해보자. 보통 이 함수를 자주 사용할거라면 아래와같이 def로 함수를 만들고 호출하여 사용할 것이다.
def get_square(a):
return a**2
print('3의 제곱은:',get_square(3))
>> 9그러나 잠깐 사용하기 위한 함수를 만들려고 lambda식을 활용하는데 위의 get_square은 아래와 동일한 함수이다.
lambda_square = lambda x : x ** 2
print('3의 제곱은:',lambda_square(3))
>> 9우선 lambda 바로 옆에있는 x는 입력값 즉 def에서의 a를 의미하고, :의 오른쪽 x**2는 return값을 의미한다.
이런 lamda식을 여러개의 값을 입력인자로 사용할 때는 map함수를 사용하여 적용하기도 한다.
a=[1,2,3]
squares = map(lambda x : x**2, a)
list(squares)
>> [1,4,9]판다스의 데이터프레임에서 lambda식을 그대로 적용할 수 있는데, apply에 lambda식을 활용하여 전체에 함수를 적용할 수 있다.
df['Name_len']= df['Name'].apply(lambda x : len(x))
df[['Name','Name_len']].head(3)
>> Name Name_len
0 Braund, Mr. Owen Harris 23
1 Cumings, Mrs. John Bradley (Florence Briggs Th... 51
2 Heikkinen, Miss. Laina 22위와 같이 name이라는 column에 len()함수를 전체 적용하여 name_len이라는 새로운 column에 할당하였다.
이러한 단순한 식말고도 복잡하게도 짤 수 있다.
df['Child_Adult'] = df['Age'].apply(lambda x : 'Child' if x <=15 else 'Adult' )
df[['Age','Child_Adult']].head(8)
>> Age Child_Adult
0 22.0 Adult
1 38.0 Adult
2 26.0 Adult
3 35.0 Adult
4 35.0 Adult
5 NaN Adult
6 54.0 Adult
7 2.0 Child위와 같이 if, else문을 이용할 수도 있다. 이때 lambda에서의 조건문은 일반적인 if else문과 다르게, if식보다 반환값을 먼저 적어주고, 그다음 조건문을 적어주고 else문과 그에 해당하는 반환값을 적는다.
그 이유는 lambda에서 : 기호 옆에 반환값이 존재해야해서 그렇다. 또한 lambda에서는 elif는 적용되지 않는다 .
'ML & DL > 파이썬 머신러닝 완벽 가이드' 카테고리의 다른 글
| 파이썬 머신러닝 완벽 가이드 Day 2 (데이터 핸들링-판다스) (0) | 2023.11.16 |
|---|---|
| 파이썬 머신러닝 완벽 가이드 Day 1 (넘파이) (0) | 2023.11.10 |