
워드임베딩은 단어를 컴퓨터가 이해하고, 효율적으로 처리할 수 있도록 단어를 벡터화하는 기술로 단어를 sparse matrix 형태로 표현한다. 이러한 과정을 거쳐 나온 것을 임베딩 벡터라고 부른다. 임베딩 벡터는 모델의 입력으로 사용되게 된다.
기계는 자연어를 이해할 수 없기 때문에 데이터를 기계가 이해할 수 있도록 숫자 등으로 변환해 주는 작업 자체를 인코딩이라고 부른다.
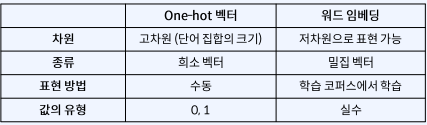
Sparse representation
원-핫 인코딩을 통해서 나온 원-핫 벡터들은 표현하고자 하는 단어의 인덱스값만 1로, 나머지는 모두 0으로 표현한 벡터이다. 이렇게 벡터 혹은 행렬의 값이 모두 0으로 표현된 것을 희소 표현이라 한다.
이렇게 만들어진 sparse matrix는 단어의 개수가 늘어나면 벡터의 차원이 한없이 커지기 때문에 단어 사전이 커질수록 필요 공간이 무한정으로 늘어나 컴퓨터의 성능이 저하될 뿐만 아니라, 표현의 효율성이 떨어진다.
또한 희소벡터는 단어의 의미를 표현하지 못하기 때문에 단어의 중의성이나 모호성을 표현하지 못한다. 따라서 이러한 원-핫 인코딩은 자연어를 표현하기에는 적합하지 않다.
Dense representation
희소표현과 반대되는 표현으로 밀집 표현이 있다. 이는 말 그대로 벡터의 차원이 조밀해졌다는 것을 의미하고, sparse matrix와 다르게 벡터의 차원을 단어 집합의 크기로 설정하지 않으며 사용자가 설정한 값으로 단어의 벡터표현의 차원을 맞춘다. 또한 단순 0과 1뿐만 아니라 다양한 실수로 벡터를 구성한다.
이 dense vector은 위에서 말했듯 단어 사전의 크기가 증가하더라도 차원의 크기가 변하지 않으므로 공간을 효율적으로 사용가능하며, 단어의 의미를 표현하기 때문에 더 큰 일반화 능력을 가지고 있다.

워드 임베딩(Word Embedding)
이렇게 단어를 희소벡터로 인코딩하는 방법도 있지만, 기본적으로 단어를 밀집벡터로 표현하는 것을 워드임베딩 이라고 부른다, 워드 임베딩을 통해 나온 밀집벡터를 임베딩 벡터라고 하며, 워드임베딩에는 `LSA`,`Word2 Vec`,`Glove` 등이 있다.
차원 축소
전통적인 방법이지만, 희소벡터를 밀집벡터의 형태로 변환할 수도 있다.
차원축소는 보통 머신러닝에서 여러 피쳐들로 구성된 고차원의 데이터에서 중요한 피쳐들을 뽑아 저차원으로 정보를 압축하는 데 사용된다. 이는 `주성분 분석(PCA)`,`잠재의미분석(LSA)`,`잠재 디리클레 할당(LDA)`,`SVD` 등이 있다.
이중 LSA와 SVD에 대하여 간단하게 알아보자.
잠재 의미 분석(Latent Sematic Analysis)
잠재 의미 분석은 기존 행렬에 특이값 분해(Singular Value Decomposition)을 통해 행렬에 속한 벡터의 차원을 축소한다.
기존에는 단어와 무선 하나를 단어 사전의 크기만큼의 차원으로 표현했다면, 각각을 축소된 차원으로 표현이 가능하다.
딱 잘라 말하면, 입력 데이터에 특이값 분해를 수행하여 차원수를 줄이고, 숨어있는 잠재의미를 파악하는 방법이다.
우선 LSA에 쓰이는 SVD에 대해서 간단하게 알아보자
특이값 분해(Singular Value Decomposition, SVD)

SVD란, 행렬 A가 mxn 크기의 행렬일 때 아래와 같이 3개 행렬의 곱으로 분해(decomposition)하는 것을 말한다.
$$ A = U \Sigma V^T $$
이 때 $ U: m $ x $ m $ 직교행렬, $ V:n $ x $ n $ 직교행렬, $ \Sigma: m $ x $ n $ 직사각 대각행렬이다.
직교행렬이란, 자신과 자신의 전치행렬의 곱 또는 이를 반대로 곱한 결과가 단위행렬이 되는 것을 말한다.
즉 $ A x A^T=I $ 를 만족하면서, $ A^T x A = I $ 를 만족하는 행렬 A이다. 이는 결국 $ A^{-1} = A^T $를 의미한다.
대각행렬(Diagonal matrix)란, 주대각선을 제외한 곳의 원소가 모두 0인 행렬을 의미한다.
$$ \Sigma = \begin{bmatrix} a & 0 & 0 \\ 0 & b & 0 \\ 0 & 0 & c \end {bmatrix} $$
일반적인 대각행렬은 위와 같고, SVD를 통해 나오는 대각행렬의 경우 주 대각원소(대각에 있는 값 a,b,c)가 모두 내림차순으로 정렬이 된다.
역행렬이란, 행렬 A와 어떤 행렬을 곱했을 때, 결과가 단위행렬이 나오게 하는 어떤 행렬을 A의 역행렬이라고 한다.
즉, $ A x A^{-1} = I $ $ 을 만족하는 것이다.

위에서 설명한 것과 같이 분해하는 것은 full SVD라고 부르는데, 이제 설명할 LSA의 경우는 각 3개의 행렬에서 일부 벡터를 삭제시켜 만든 truncated SVD를 사용한다. 이는 대각 행렬 $ \Sigma $의 대각원소 중 상위값 t개만 남기고, U와 V행렬의 t열까지만 남기는 것을 의미하며, 이렇게 절단하면 기존 행렬 A는 복구할 수 없다. 이 t는 매개변수이며 크게 잡으면 기존의 행렬 A로부터 다양한 의미를 가져갈 수 있지만, t를 작게 잡아야만 노이즈를 제거할 수 있다.

19-01 잠재 의미 분석(Latent Semantic Analysis, LSA)
LSA는 정확히는 토픽 모델링을 위해 최적화 된 알고리즘은 아니지만, 토픽 모델링이라는 분야에 아이디어를 제공한 알고리즘이라고 볼 수 있습니다. 이에 토픽 모델링 알고리즘인 LD…
wikidocs.net
다시 LSA로 돌아가면, 기존의 DTM이나 TF-IDF행렬의 경우는 단어의 의미를전혀 고려하지 못하였다. LSA는 이러한 DTM과 TF-IDF 행렬에 truncated SVD를 사용하여 차원을 축소시키고, 단어들의 잠재의미를 끌어내는 알고리즘이다.
각 행렬을 특이값 분해를 하개되면 r개의 특이값이 남고, 위에서 설명했듯 $ \Sigma $의 대각원소는 내림차순으로 정렬이 되기 때문에 사용자가 t를 정해주면, 중요한 특이값 t개만 남고 제거된다. 마찬가지로 U와 V행렬에서도 t 줄만 남기는데, 이것이 중요한 정보만 뽑아내는 과정이다. 이러한 LSA는 토픽 모델링에서 쓰이는 기술이다.
나중에 LSA에 대하여 더 자세하게 적어보겠지만, 이 LSA의 장점은 빠르게 구현 가능하며 차원축소를 한다는 것이고, 단점은 문서에 포함된 단어가 정규분포를 따라야하며, 새로운 문서나 단어가 추가되면 처음부터 작업을 새로 해야 한다는 것이다.
간단한 워드임베딩 실습
keras에서 제공되는 Embedding()은 단어를 랜덤한 값을 가지는 밀집 벡터로 변환한 뒤, 인공신경망의 가중치를 학습하는 것과 같은 방식으로 단어 벡터를 학습한다.
이 keras의 Embedding layer은 크기가 (samples_length, sequence_length)인 2d 정수 텐서를 입력으로 받는다.
밀집벡터는 위에서 설명했듯 입력길이와 상관없이 항상 고정된 임의의 크기의 벡터로 인코딩하기 때문에 가변길이의 입력시퀀스를 임베딩할 수 있다.
이번 실습에서는 IMDB 영화 리뷰 감성 예측을 진행해볼 것이다.
우선 데이터를 다운받은 뒤, 영화리뷰에서 가장 빈도가 높은 10000개의 단어를 추출하고, 20개 이상의 단어로 구성된 리뷰들만 추출한 뒤 Embedding layer을 해당 수집한 것과 맞게 10000,20으로 크기를 정해준다.
import tensorflow
from tensorflow.keras.layers import Embedding
from tensorflow.keras.datasets import imdb
from tensorflow.keras import preprocessing
max_features= 10000
max_len=20
(x_train,y_train),(x_test,y_test) = imdb.load_data(num_words=max_features)
x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=max_len)
x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=max_len)우선 모델을 `Sequential`로 불러오면 layer을 하나씩 쌓을 수 있다.
이후 출력크기를 정해주고, input_length는 위에서 정한 20개가 된다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten,Dense,Embedding
model = Sequential()
model.add(Embedding(10000,8,input_length = max_len))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss = 'binary_crossentropy', metrics = ['accuracy'])
model.summary()
history= model.fit(x_train,y_train,epochs=30,batch_size=32,validation_split=0.2)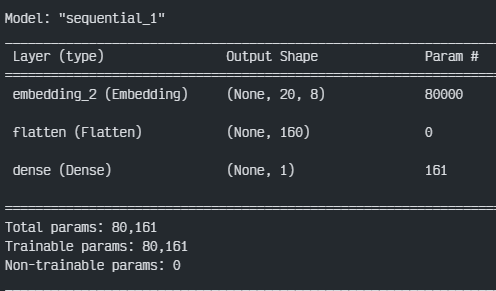
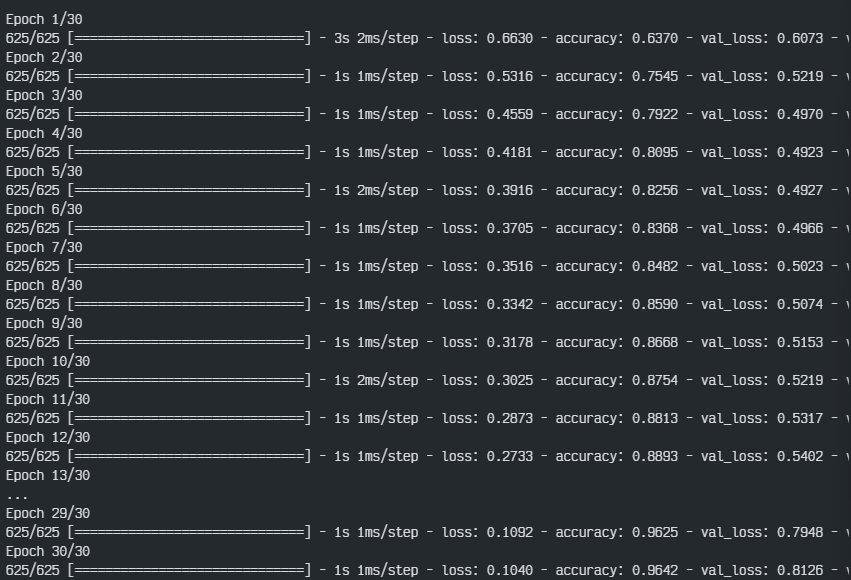
단순 accuracy만 보면 validation set에 대하여 70%정도의 정확도가 나왔으나, Dense layer을 한 개만 넣어서 각 단어를 독립적으로 다뤘기 때문에 단어 사이의 관계나 문장의 구조는 고려하지 않았을 것이다.
이번실습에서는 랜덤한 가중치로 초기화된 Embedding layer을 사용했지만 다른 embedding기법등을 통하여 임베딩된 벡터들을 넣는다면 더 일반화된 정보들을 학습할 수 있을 것이다.
'ML & DL > NLP' 카테고리의 다른 글
| [패캠/NLP] Word2Vec 워드 임베딩 실습 (1) | 2023.12.20 |
|---|---|
| [패캠/NLP] 임베딩 기법(Word2Vec, FastText, GloVe) (1) | 2023.12.20 |
| [패캠/NLP] 문장 임베딩 및 유사도 측정 실습 (1) | 2023.12.18 |
| [패캠/NLP] 자연어 특성과 임베딩 (0) | 2023.12.14 |
| 형태소 분석과 전처리 실습 (0) | 2023.12.07 |