
이번에는 순환신경망: RNN과 RNN의 한계를 보완하여 나온 LSTM, GRU에 대하여 공부해 볼 것이다. 이는 아주 많이 쓰이는 모델 구조이기 때문에 잘 알아두면 좋을 것이다.
0. 순환신경망의 등장
기존에 딥러닝은 합성곱신경망을 기반으로 많이 발전을 했었다. 그런데 이러한 합성곱 신경망은 고정된 크기의 입력과 출력을 처리하도록 설계되었다. 따라서 고정된 크기를 요구하는 이미지 분류 등의 task에는 훌륭했다. 이러한 합성곱 신경망에서는 모델 학습 때와 동일한 사이즈로 입력을 resize 해줌으로써 사용할 수 있었다.
그러나 텍스트, 음성 등은 길이가 고정되어있지 않은 sequence 데이터이고, 이러한 seqeunce데이터는 고정된 크기가 아닐뿐더러 과거의 정보를 기억하면서 현재의 입력도 동시에 처리해야 한다는 성질을 가졌었다.
이에 RNN: Recurrent Neural Network가 등장하였다.
1. 순환신경망, RNN:Recurrent Neural Network
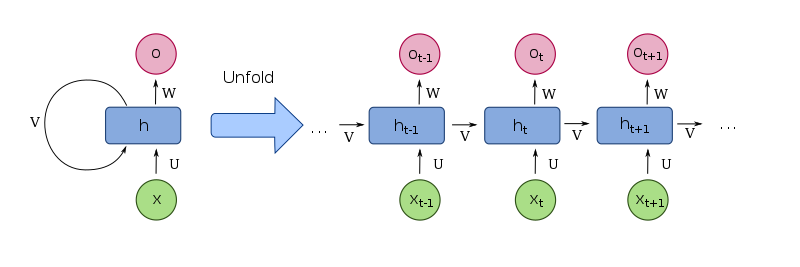

순환신경망의 핵심은 이전 시점의 정보를 현재 시점의 입력과 함께 처리하는 순환 구조이다. 이를 통해 순환 신경망은 시퀀스 내의 정보를 기억할 수 있다. 은닉상태(hidden state)는 순환신경망의 핵심적인 요소로써, 네트워크가 시간에 따라 어떤 정보를 기억할지를 결정하는 역할을 한다.
1-1. 순환신경망 구조
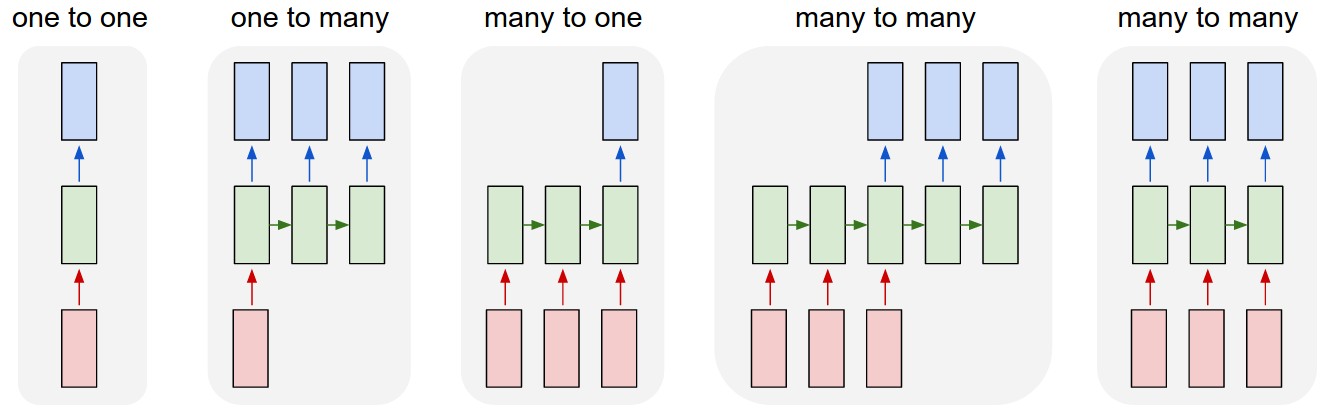
모델구조에는 여러 가지 방식이 있는데, 제일 기본적인 방식이 하나의 입력 데이터에 대해 하나의 출력 데이터가 나오는 one to one 이 있고, image captioning 같은 데서 사용되는 하나의 입력에 대한 여러 출력형태인 one to many도 있으며, 감성분석에서 사용되는 여러 문장을 확인하여 긍정/부정을 내는 여러 개의 입력을 통해 하나의 출력을 many to one 구조도 있다. 다음으로 기계번역과 비디오의 장면 분류 같은 데에는 many to many 구조도 사용된다.
이러한 many의 입력 혹은 출력을 갖는 구조를 처음 도입한 것이 RNN이다.
순환신경망은 순차적인 데이터나 시계열 데이터 처리에 특화된 신경망 구조로, 각 시간 단계에서의 출력이 이전 단계의 정보를 포함한다. 즉 이전 시간 스텝의 정보가 현재 상태와 출력에 영향을 준다.
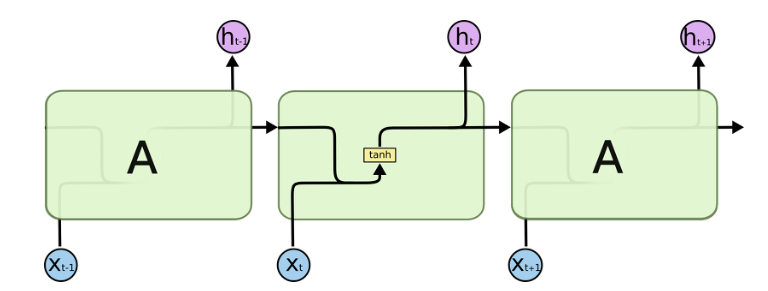
위의 그림에서 현재 타임스텝을 t라고 할 때, 현재 타임스텝의 입력값 $X_t$와 이전 시점 t-1의 hidden state값인 $h_{t-1}$이 가중치와 곱해져서 활성화함수(tanh)를 거쳐 가중치를 곱하여 출력이 나가고, 가중치를 곱하지 않고 다음 hidden state로 넘어간다. 즉 다음과 같은 식이 성립한다. $$ h_t=tanh(W_xx_t + W_hh_{t-1}+b) $$
1-2. RNN의 한계
이렇게 이전 셀의 hidden state를 넘겨주면서 갱신함에 따라 이전 시퀀스의 정보를 기억할 수 있게 되었는데 한계점이 있었다. 시퀀스가 길어질수록 앞부분의 정보를 잊어버리는 즉 앞부분(입력과 가까운 부분)의 가중치 업데이트가 잘 안 되는 `Long-Term Dependency: 장기의존성` 문제가 발생하였다. 이 문제를 해결하기 위해서 RNN구조를 본떠 새로운 모델이 개발되었다. 여기서는 장기의존성 문제라고 부르지만, 인공신경망에서 레이어가 깊어질수록 발생하는 Gradient Vanishing 문제와 같은 문제이다.
1-3. RNN 정리
이러한 RNN의 장점과 단점을 정리해보면 다음과 같다.
[장점]
- 모든 길이의 시퀀스를 입력으로 처리할 수 있다.
- 시간에 따라 가중치를 공유하며, 입력 시퀀스가 길어져도 모델 크기가 증가하지 않는다.
- 과거 정보를 고려하여 다음 시간의 출력을 계산한다.
[단점]
- 매번 시간에 따른 출력을 계산하여 병렬 처리가 불가능하며 계산 속도가 느리다.
- 입력 혹은 출력 시퀀스가 길어지면 오래된 정보를 반영하기 어려움(Long-Term Dependency)
- 현재 상태에 대한 미래 입력을 고려할 수 없다.
2. LSTM: Long Short Term Memory
LSTM, Long Short Term Memory는 순환 신경망의 단점인 장기 의존성 문제를 완화하기 위하여 설계된 모델이다.
간단하게 말하자면, `입력`,`출력`,`망각` 게이트라는 개념을 도입하여 정보를 조절한다.
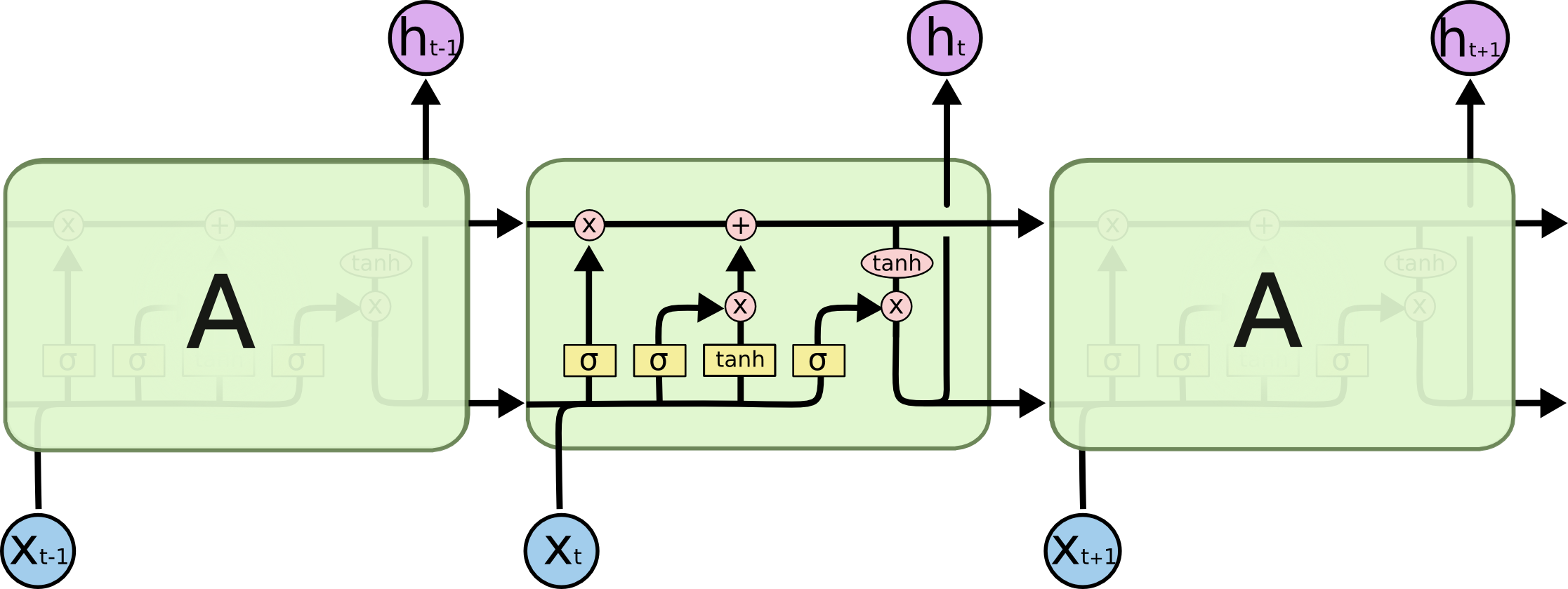
위의 LSTM 셀구조를 좀 더 자세하게 보자.
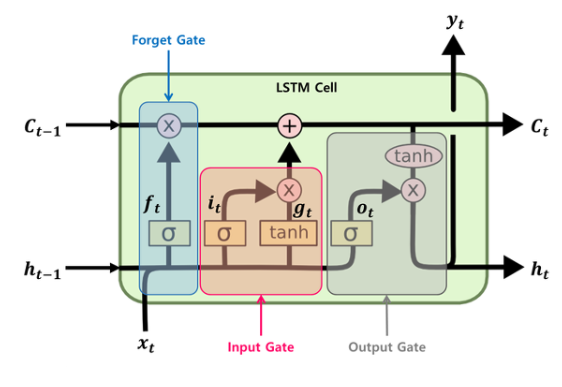
0. $C_t$, `Cell state`는 정보가 바뀌지 않고 그대로 흐르도록 하는 역할을 한다.
이는 이후 forget gate와 inputgate에 따라 정보가 변경된다
1. `Forget Gate: 망각 게이트`는 LSTM의 가장 첫 단계 중 하나로, 기존 정보(이전 cell state) 중 어떤 정보를 버릴지를 선택한다.
$$ f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) $$
이전 시간의 히든 스테이트 $h_{t-1}$ 과 현재 입력 $x_t$을 연결한 벡터에 forget 게이트의 가중치를 곱한 것에 시그모이드 함수를 적용하여 출력값의 결과가 1에 가까울수록 정보를 보존하고, 0에 가까울수록 정보를 잊는다.
2. `Input Gate:입력 게이트`는 새로운 입력 데이터 중 어떤 정보를 다음 상태로 저장할지를 결정한다.
$$ i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) $$
input gate 또한 이전 스텝의 히든 스테이트에 현재 입력 $x_t$을 연결한 벡터에 input 게이트의 가중치 행렬을 곱하고 시그모이드함수를 곱해서 어떤 정보를 업데이트할지 정한 후, 활성화함수 layer에서 새로운 후보 벡터($c_t$)를 생성한다. 활성화함수 레이어를 거치는 부분은 다음과 같다. $$ \tilde {c}_t=\tanh(W_c \cdot [h_{t-1}, x_t] + b_c) $$
이렇게 Forget Gate와 Input Gate에서 나온 값들을 이용하여 Cell state를 업데이트한다.
$$ c_t = f_t \cdot c_{t-1} + i_t \cdot \tilde{c}_t $$
3. `Output Gate:출력 게이트`는 다음 상태에 어떤 정보를 내보낼지를 선택한다.
먼저 시그모이드 레이어에 input data를 넣어서 output을 정하고, cell state를 tanh 레이어에 넣어서 시그모이드에서 나온 output과 곱하여 최종 output을 생성한다.
$$ o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) $$ $$ h_t = o_t \cdot \tanh(c_t) $$
3. GRU: Gated Recurrnt Unit
그 다음으로 나온 게 LSTM을 보다 단순화한 구조로 표현하기 위하여 2개의 gate 구조로 구현한 GRU 모델이다.
이는 LSTM보다 적은 파라미터로 유사한 성능을 낼 수 있어 비용 효율적이다.
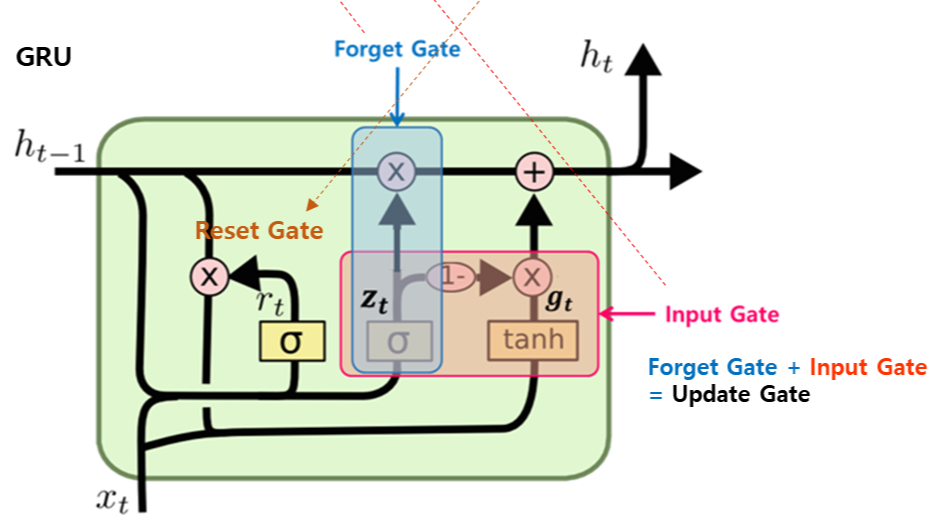
GRU는 `Reset Gate`와 `Update Gate`로 구성되어 있다.
`Update Gate`는 이전 LSTM의 Forget Gate와 Input Gate를 합친 역할을 하며,
`Reset Gate`는 Output Gate와 유사한 역할을 한다.
1. Update Gate에서는 우선 시그모이드 함수를 거친 $x_t$가 Forget Gate처럼 이전 정보의 비율을 결정하고, 해당 출력값이 $z_t$일 때 나머지 $1-z_t$가 현재 정보의 비율을 의미하기 때문에 Input Gate 역할을 한다.
$$ z_t = \sigma(W_z \cdot [h_{t-1}, x_t]) $$
2. Reset Gate에서는 이전 정보에서 얼마만큼을 선택해서 내보낼지를 결정하는데, LSTM의 Output Gate에서는 최종출력에서 나갈 정보를 정하는 것이라면, 여기서는 이전 정보에서 미리 내보낼정도를 정하는 것이다.
$$ r_t = \sigma(W_r \cdot [h_{t-1}, x_t]) $$
이후, Hidden state를 업데이트하게 되는데, 우선 이전 $h_{t-1}$에 reset gate의 결괏값을 곱하여 내보낼 정보를 선별하고, 활성화 함수를 적용하여 -1~1 사이의 값으로 바꾸고, update gate에서 구해진 새로운 정보를 반영할 비율 $1-z_t$를 곱하여 이전 정보 중 내보낼 값을 계산한다. 마지막으로 update gate에서 구해진 이전 정보의 비율 $z_t$에 이전 정보 $h_{t-1}$을 곱하여 이전 정보 중 내보낼 값을 계산하고 이를 반영할 새로운 정보와 더하여 hidden state값을 업데이트한다.
$$ g_t = \tanh(W_{xg} \cdot x_t + W_{hg} \cdot (r_t \odot h_{t-1}) + b_g) $$
$$h_t = (1 - z_t) \odot g_{t} + z_t \odot h_{t-1}$$
사실 이렇게 말로 해서는 정리가 안되지만, 위의 그림을 보면서 차근차근 따라가 보면 이해가 갈 것이다.
'ML & DL > 개념정리' 카테고리의 다른 글
| 가중치 초기화, 규제, 학습 (0) | 2023.12.26 |
|---|---|
| 성능 고도화 기법 (0) | 2023.12.23 |
| CNN: Convolution Neural Network (0) | 2023.12.21 |
| PyTorch 시작 (0) | 2023.12.21 |
| 손실 함수(Loss function) (1) | 2023.12.21 |