0. BERT 등장

BERT는 Google의 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 논문에서 처음 제안된 모델로, 이전의 Transformer의 인코더 기반의 언어 모델이다. 우선 unlabeld data로부터 pre-train을 진행한 후, 전이학습을 하는 모델이며, 하나의 output layer을 pre-trained BERT에 추가하여 다양한 NLP task에서 SOTA를 달성하였다.
기존의 사전학습된 벡터 표현을 이용하는 방법은 크게 2가지가 존재하였다.
0-1. feature based approach
대표적으로 ELMo가 있으며, pre-trained representations를 하나의 feature로 활용하여 사용하였다.
0-2. fine-tuning approach
task specific parameters는 최소화하고, 모든 pre-trained 파라미터를 조금만 바꿔서 학습하였다.
위의 두 가지 접근방식 모두 사전학습 과정에서 동일한 목적함수를 공유하는데 일반적인 언어표현을 학습하기 위해서 uni-directional 언어 모델을 사용하였다. 그러나 이러한 방법이 representation pre-training의 성능을 떨어뜨린다고 강조하였는데, 그 예시로 GPT를 들며 모든 토큰이 이전 토큰과의 attention만 계산된다고 하였다.(uni-directional). 또한 QA 같은 task에서는 context의 양방향을 포함하는 것이 매우 중요하기 때문에 위와 같은 방식들이 성능을 떨어뜨린다고 강조하며 `deep bidirectional context`를 포함한 BERT를 발표했다.
1. BERT
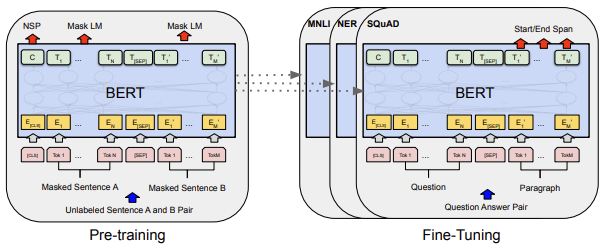
논문에서 BERT를 `Pre-training part`와 `Fine-tuning part`로 나누어 설명하는데, Pre-training에서는 다양한 사전학습된 task의 unlabeled data를 활용하여 파라미터를 설정하고 이를 바탕으로 학습된 모델은 Fine-tuning 단계에서 진행하고자 하는 task의 labeled data를 이용하여 파인튜닝을 진행한다.
BERT모델의 구조는 `multi-layer bidirectional Transformer encoder`, 양방향 트랜스포머 인코더를 여러층으로 쌓은 것을 의미한다. ( GPT는 다음 token을 맞추는 언어모델을 만들기 위해서 decoder 부분을 사용하였고, BERT는 MLM, NSP task를 위한 self-attention을 수행하는 encoder 부분을 사용했다.)
1-1. BERT 입/출력
BERT가 다양한 downstream task에 잘 적용되기 위해선, input representation이 명확해야했다.
이를 위해 총 3가지의 Embedding vector(Token embedding + Segment embedding + Position embedding)을 사용했다.

위와 같이 Input sequence는 한 쌍의 문장으로 구성되고, 문장의 각 문장들은 [SEP] 토큰으로 분리하였으며, 각 문장을 구분하기 위해서 Segment Embedding을 사용하였다. Token embedding은 WordPiece embedding을 사용하였다.
WordPiece embedding은 자주 등장하는 sub-word는 하나의 단위로 정하고, 자주 등장하지 않는 단어는 sub-word로 쪼개는 방식을 사용한다. 이 방식은 OOV 처리에도 강건하며 모든 언어에 적용이 가능한 방식이다.
EX)
Word : Jet makers feud over seat width with big orders at stake
Wordpieces: _J et _makers _fe ud _over _seat _width _with _big _orders _at _stake
자주 등장하는 makers나 over, seat 등은 하나의 단위, Jet 같은 단어는 _J et
1-2. MLM: Masked Language Modeling
MLM이란, Masked Language Model로 문장에서 임의의 Token을 마스킹하고 그 Token을 맞추는 방식의 학습을 진행한다. 즉 빈칸 채우기를 진행한다. 실험결과 15%를 mask 할 때 가장 선능이 좋았다고 하며 이 [MASK] 토큰은 pre-training에만 사용되고 fine-tuning 과정에서는 사용되지 않는다.


그런데, fine tuning 단계에서는 [MASK] 토큰이 안 들어오기 때문에 사전학습과 파인튜닝 과정 간의 mismatch가 발생하고 이를 방지하기 위해 전체 15%의 [MASK] 토큰에 추가적인 작업을 진행한다. 그 [MASK] 토큰에서 80%는 [MASK] 토큰으로 바꾸고, 10%는 random word로 바꾸고, 10%는 원래 단어 그대로 나누는 방식을 사용했다.
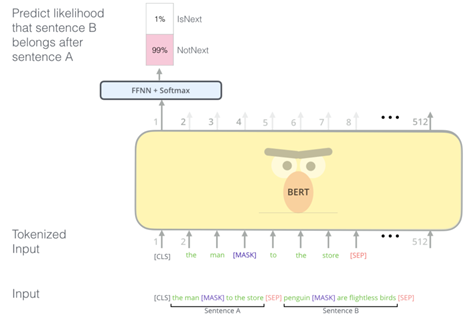
1-3. NSP: Next Sentence Prediction
많은 NLP의 downstram task들은 두 문장 사이의 관계를 이해하는 것이 중요하다. 이를 학습하기 위해 BERT 모델은 NSP를 이용하였는데, 이는 두 문장이 주어졌을 때 첫 번째 문장의 바로 다음에 오는 문장인지를 예측하는 방식으로 학습을 진행한다. 이를 위해 문장 A와 B를 선택할 때 50%는 실제 A의 다음 문장인 B를 선택, 나머지 50%는 다른 랜덤 한 문장을 고르는 방식이다.

1-3. Pretraining data
사전학습 과정은 매우 많은 데이터를 필요로 하기 때문에, corpus 구축을 위해서 BooksCorpus에서 8억 개 정도의 단어와 English Wikipedia의 약 25억 개의 단어를 사용하여 학습하였다.
1-4. Finetuning
파인튜닝의 과정은 Transformer의 self-attention 구조로 인해 많은 downstream task를 모델링할 수 있었다.

또한 output도 각 task에 맞게 변환해 줬다.
이러한 fine-tuning에 필요한 데이터는 작아도 되기 때문에 비용과 시간을 절약할 수 있었다.
2. BERT 결과
BERT는 GLUE라는 NLU 능력을 평가하기 위한 9가지 Task로 구성된 데이터셋에 맞게 fine-tuning을 진행하여 SOTA를 달성하였다.

3. 결론
정리하자면 ELMo가 pretraining이라는 관점을 제시하여, GPT-1에서 pre-training을 Transformer에 적용하였고, BERT는 양방향을 통해 개선시켰다.
이 BERT모델이 발표된 이후 다양한 모델들이 개발되었으나, BERT계열의 모델은 학습시간도 매우 오래 걸리며 사전학습에 많은 시간과 비용이 소모된다. 또한 일반 도메인 데이터로 학습되어서 일반적인 자연어처리에는 매우 훌륭하지만 특정 도메인에 대해서는 아직 부족하다. 이러한 것들은 파인튜닝으로 해결해야 한다.

참고
BERT를 파해쳐 보자!!
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 최근 BERT 라는 이름의 모델이 많은 자연어처리 분야에서 지금껏 state-of-the-art 였던 기존 앙상블 모델을 가볍게 누르며 1위를 차지했
keep-steady.tistory.com
[최대한 자세하게 설명한 논문리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- References https://arxiv.org/abs/1810.04805?source=post_page (논문 원본) 해당 포스팅은 BERT 논문을 자세히 읽으며 공부한 내용들을 논문의 목차 순서대로 정리한 것이다. 0. Abstract BERT가 unlabeled text로부터 deep
hyunsooworld.tistory.com
[논문 리뷰] BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding (NAACL 2019)
2019년 구글에서 발표한 BERT에 대한 논문이다. 논문의 원본은 여기서 볼 수 있다. # Introduction Pre-trained Language Model은 자연어 처리 task의 성능을 향상시킬 수 있다. PLM(pre-trained language model)을 적용하
misconstructed.tistory.com
'ML & DL > NLP' 카테고리의 다른 글
| 한 권으로 끝내는 랭체인 노트 따라하기 Day 1 (0) | 2024.12.23 |
|---|---|
| 한 권으로 끝내는 랭체인 노트 따라하기 Day 0 (0) | 2024.12.20 |
| [패캠/NLP] GPT (0) | 2023.12.27 |
| [패캠/NLP] Transformer: 트랜스포머 (0) | 2023.12.26 |
| [패캠/NLP] 문장 임베딩 ELMo (1) | 2023.12.22 |