
오늘은 어제 알리바바 클라우드의 Qwen 팀에서 공개한 Qwen3-ASR에 대해서 알아보려 한다.
2026년 1월 29일에 출시된 따끈따끈한 모델인데, 음성 인식(ASR) 분야에서 꽤 혁신적인 접근을 보여주고 있어서 정리해 봤다.
Qwen3-ASR은 알리바바 클라우드의 Qwen 팀이 만든 오픈소스 자동 음성 인식(ASR) 모델이다.
단순히 음성을 텍스트로 바꾸는 데서 그치지 않고, 언어 식별부터 타임스탬프 예측까지 한 번에 처리할 수 있다는 게 특징이다.
모델은 두 가지 버전으로 나왔다:
- Qwen3-ASR-0.6B: 가벼운 버전, 속도가 미친 듯이 빠름
- Qwen3-ASR-1.7B: 성능 위주 버전, 오픈소스 중 최고 수준
여기에 더해 Qwen3-ForcedAligner-0.6B라는 보조 모델도 있는데, 이건 음성과 텍스트를 정밀하게 정렬해서 단어 단위로 타임스탬프를 붙여주는 역할을 한다.
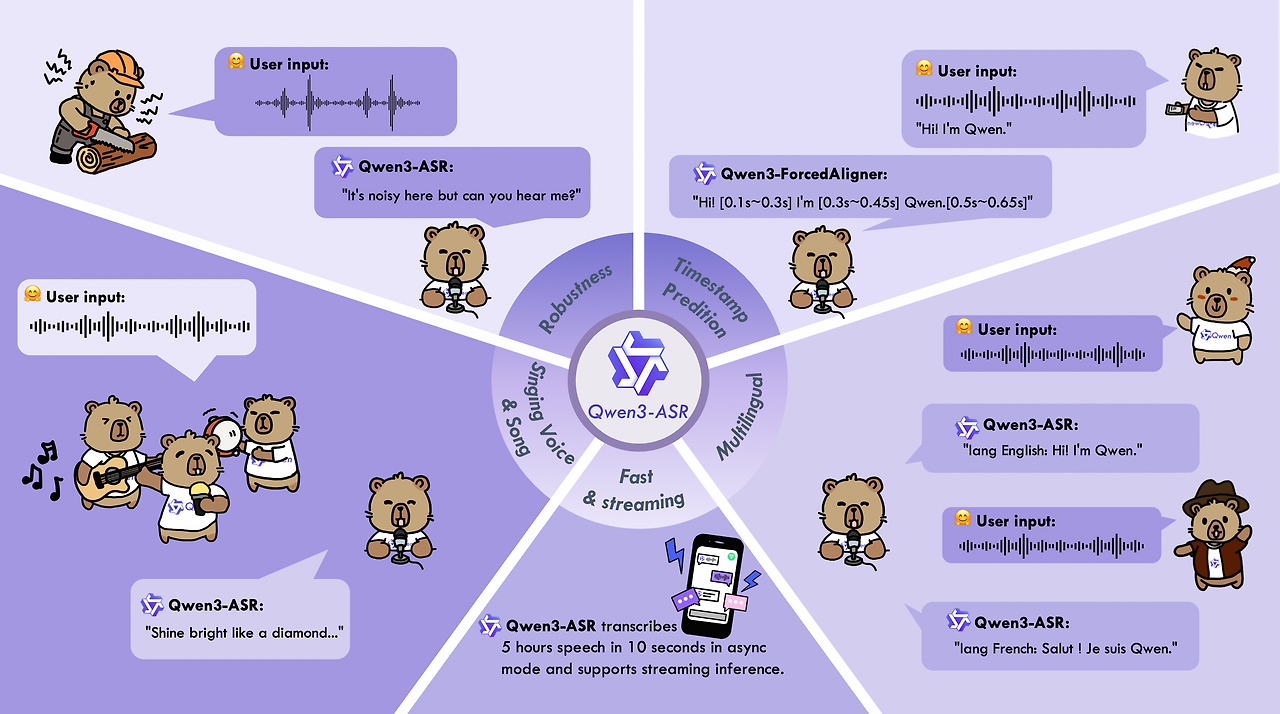
Feature
1. All-in-one
이 모델이 지원하는 언어를 보고 좀 놀랐다
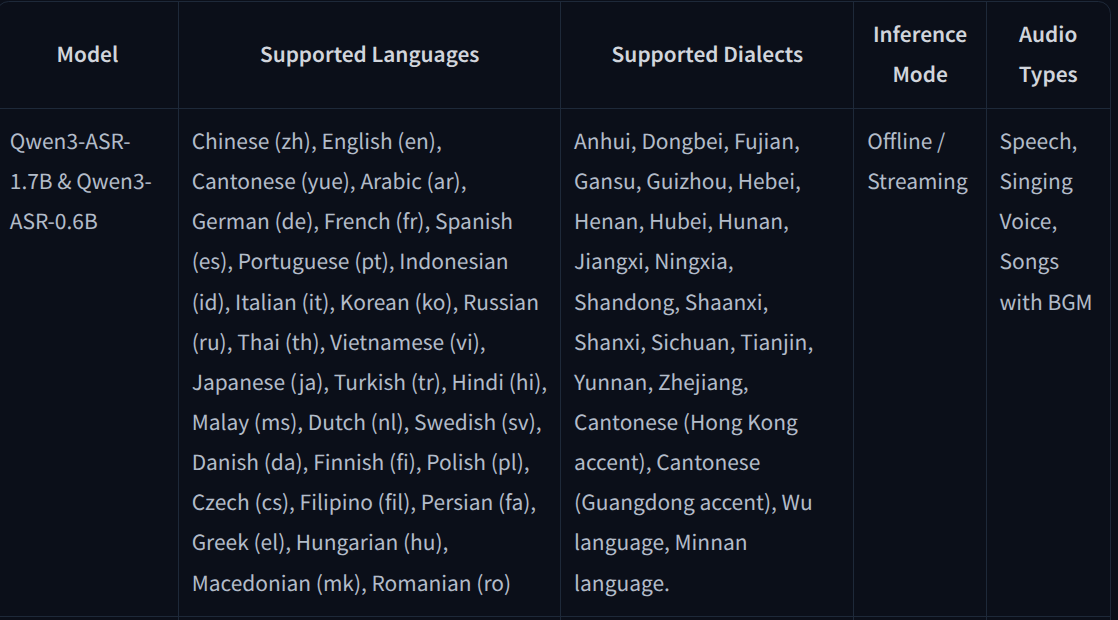
우선 한국어 ASR 모델이 많이 없는데, 한국어가 된다는 것에 매우 감사했고, 엄청나게 다양한 언어들을 지원할 뿐만 아니라 자동언어 식별 기능이 내장되어 있어서, 어떤 언어인지 미리 알려주지 않아도 알아서 판단한다.
2. Excellent and Fast
벤치마크 결과를 보면 확실히 알 수 있다:
| 데이터셋 | Whisper-large-v3 | Qwen3-ASR-0.6B | Qwen3-ASR-1.7B |
|---|---|---|---|
| Librispeech (clean) | 1.51 | 2.11 | 1.63 |
| GigaSpeech | 9.76 | 8.88 | 8.45 |
| WenetSpeech (net) | 9.86 | 5.97 | 4.97 |
| 언어 식별 정확도 (평균) | 94.1% | 96.8% | 97.9% |
특히 WenetSpeech에서 Whisper의 절반 수준인 4.97을 기록한 건 꽤 인상적이었다. OpenAI의 Whisper-large-v3가 음성 인식의 강자로 여겨졌는데, 드디어 제대로 된 경쟁자가 나온 셈이다.(자세한 벤치마크는 HF에 나와있다)
3. 스트리밍과 배치 처리 둘 다 된다
보통 ASR 모델은 스트리밍용이랑 오프라인용을 따로 만드는 경우가 많은데, Qwen3-ASR은 단일 모델로 두 가지를 다 지원한다. 실시간 음성 인식이 필요할 때도, 이미 녹음된 파일을 처리할 때도 같은 모델을 쓸 수 있다는 것이다.
게다가 5분 이상의 긴 오디오도 문제없이 처리한다고 한다. 팟캐스트나 강의 같은 긴 콘텐츠에도 바로 적용 가능하겠다.
4. Novel and strong forced alignment Solution
Qwen3-ForcedAligner-0.6B를 함께 쓰면 단어/문자 수준의 타임스탬프를 얻을 수 있다. 이게 왜 중요하냐면, 자막 생성이나 음성 분석 같은 작업에 필수적이기 때문이다. 강제 정렬(Forced Alignment) 성능도 기존 모델들을 압도한다:
이건 글 하단에서 다루도록 하겠다.
- 중국어: 33.1ms (기존 NFA는 109.8ms)
- 영어: 37.5ms (기존 WhisperX는 92.1ms)
- 평균: 42.9ms (기존은 129.8~161.1ms)
평균 오차가 42.9ms라는 건, 거의 눈 깜빡할 새도 없는 수준의 정확도다.
How to use
설치부터 실행까지 생각보다 간단했다.
1. 설치
conda create -n qwen3-asr python=3.12 -y
conda activate qwen3-asr
# 기본 설치
pip install -U qwen-asr
# vLLM 백엔드 포함 (더 빠름, 권장)
pip install -U qwen-asr[vllm]나는 vLLM 버전으로 설치했는데, 속도가 확실히 체감될 정도로 빨랐다.
2. 기본 사용법 (Transformers 백엔드)
import torch
from qwen_asr import Qwen3ASRModel
# 모델 로드
model = Qwen3ASRModel.from_pretrained(
"Qwen/Qwen3-ASR-1.7B",
dtype=torch.bfloat16,
device_map="cuda:0",
max_inference_batch_size=32,
max_new_tokens=256,
)
# 음성 인식 실행
results = model.transcribe(
audio="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_en.wav",
language=None, # 자동 언어 식별
)
print(results[0].language) # 언어 출력
print(results[0].text) # 인식된 텍스트language=None으로 설정하면 자동으로 언어를 감지해 준다. 이게 진짜 편한 게, 여러 언어가 섞인 데이터를 처리할 때 일일이 지정 안 해줘도 된다는 것이다.
2-1. vLLM으로 더 빠르게
import torch
from qwen_asr import Qwen3ASRModel
if __name__ == '__main__':
model = Qwen3ASRModel.LLM(
model="Qwen/Qwen3-ASR-1.7B",
gpu_memory_utilization=0.7,
max_inference_batch_size=128,
max_new_tokens=4096,
)
results = model.transcribe(
audio=[
"https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_zh.wav",
"https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_en.wav",
],
language=["Chinese", "English"],
)
for r in results:
print(r.language, r.text)vLLM 백엔드는 배치 처리에 최적화되어 있어서, 여러 파일을 한꺼번에 처리할 때 훨씬 효율적이다. 공식 문서에 따르면 0.6B 모델의 경우 동시성 128일 때 2000배 처리량을 보여준다고 한다.
2-2. 타임스탬프 포함 인식
results = model.transcribe(
audio=["audio1.wav", "audio2.wav"],
language=["Chinese", "English"],
return_time_stamps=True,
forced_aligner="Qwen/Qwen3-ForcedAligner-0.6B",
)
for r in results:
print(r.language, r.text, r.time_stamps[0])return_time_stamps=True만 추가하면 각 단어가 언제 시작하고 끝나는지 정확한 시간 정보를 얻을 수 있다.
3. OpenAI API compatible server
vLLM으로 서버를 띄우면 OpenAI API 형식으로 호출할 수 있다. 이미 OpenAI SDK를 쓰고 있다면 엔드포인트만 바꾸면 된다는 것이다.
3-1 vllm 서빙
vllm serve Qwen/Qwen3-ASR-1.7B3-2.Python request
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="EMPTY"
)
response = client.chat.completions.create(
model="Qwen/Qwen3-ASR-1.7B",
messages=[{
"role": "user",
"content": [{
"type": "audio_url",
"audio_url": {"url": "https://...asr_en.wav"}
}]
}],
)
print(response.choices[0].message.content)3-3. cuRL request
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [{
"role": "user",
"content": [{
"type": "audio_url",
"audio_url": {"url": "https://...asr_en.wav"}
}]
}]
}'이렇게 하면 기존 시스템에 통합하기가 훨씬 쉬워진다. OpenAI의 Whisper API를 쓰고 있었다면 거의 그대로 교체 가능한 수준이다
Qwen3-ForcedAligner
Forced Alignment는 음성과 텍스트를 정밀하게 맞추는 기술이다. 쉽게 말해, "이 단어는 정확히 몇 초부터 몇 초까지 말했다"는 정보를 자동으로 찾아내는 것이다.
이 기능은 자막 제작, 음성 분석, 언어 학습 앱 등에서 필수적이다. 예를 들어:
- 자막 싱크: 영상과 자막의 타이밍을 정확하게 맞춤
- 음성 분석: 특정 단어가 언제 나왔는지 추적
- 언어 학습: 발음 교정 시 단어별 발음 시간 측정
전통적인 도구로는 Montreal Forced Aligner(MFA)가 유명한데, 설정이 복잡하고 언어별로 따로 모델을 관리해야 했다.
WhisperX 같은 최신 ASR 기반 방법도 나왔지만, 정확도가 기대만큼은 아니었다.
Qwen3-ForcedAligner는 NAR(Non-Autoregressive) 방식을 쓴다. 기존의 순차적 방식과 달리 한 번에 모든 타임스탬프를 예측해서 속도가 빠르고, 11개 언어를 단일 모델로 처리한다.(이것도 11개 언어 중에 한국어가 포함되어 있어서 너무 기쁘다)
성능 비교를 보면 차이가 명확하다:
| 언어 | WhisperX | NFA | Qwen3-ForcedAligner |
|---|---|---|---|
| 중국어 | - | 109.8ms | 33.1ms |
| 영어 | 92.1ms | - | 37.5ms |
| 평균 | 161.1ms | 129.8ms | 42.9ms |
3배 이상 정확하다는 것이다. 실제로 써보면 자막이 거의 완벽하게 동기화되는 걸 볼 수 있다.
ASR 없이 Forced Aligner만 쓸 수도 있다:
import torch
from qwen_asr import Qwen3ForcedAligner
model = Qwen3ForcedAligner.from_pretrained(
"Qwen/Qwen3-ForcedAligner-0.6B",
dtype=torch.bfloat16,
device_map="cuda:0",
)
results = model.align(
audio="audio.wav",
text="甚至出现交易几乎停滞的情况。",
language="Chinese",
)
# 각 단어의 시작-종료 시간 출력
for word in results[0]:
print(word.text, word.start_time, word.end_time)이미 텍스트를 알고 있을 때(예: 대본이 있는 영상) 정확한 타이밍만 필요하면 이렇게 쓸 수 있다.
Docker를 선호한다면 공식 이미지를 쓸 수 있다:
LOCAL_WORKDIR=/path/to/workspace
docker run --gpus all --name qwen3-asr \
-v /var/run/docker.sock:/var/run/docker.sock \
-p 8000:80 \
--mount type=bind,source=$LOCAL_WORKDIR,target=/data/shared/Qwen3-ASR \
--shm-size=4gb \
-it qwenllm/qwen3-asr:latest--gpus all은 GPU를 쓰기 위한 옵션이고, --shm-size=4gb는 공유 메모리를 충분히 확보하기 위한 것이다. 배치 처리를 할 때 메모리가 부족하면 에러가 날 수 있어서 이 부분은 꼭 설정해 주는 게 좋다.
마무리
요즘 HuggingFace를 하루에 몇백 번씩 들락날락거리면서 추세를 보아하니 한 두세 달 전까지는 VLM기반의 OCR 모델들이 열풍이었고(아직도 계속해서 출시되고 있는데 이제 경량화에 들어간 모습),
얼마 전부터는 ASR, TTS 등의 task를 가진 모델들이 치열하게 경쟁 중인 것 같다.
Qwen3-ASR-1.7B는 오픈소스 음성 인식 분야에서 꽤 의미 있는 발전이라고 생각한다. Whisper가 나왔을 때도 놀라웠는데, 이번에는 더 빠르고 정확한 모델이 Apache 2.0 라이선스로 나왔다는 게 반갑다.
즉 핵심은 이 3가지다!!
- 다국어 지원: 30개 언어 + 22개 방언을 단일 모델로 처리
- 상용급 성능: Whisper와 경쟁 가능한 수준의 정확도
- 타임스탬프: Forced Aligner로 단어 단위 정밀 정렬
나중에 시간 나면 실제 프로젝트에 적용해 보고 후속 편을 써볼 예정이다. 궁금한 점이나 더 자세한 내용은 공식 Github이나 HuggingFace 모델 카드를 참고하길 바란다!
추가로 방금 전 Technical Report도 공개되었으니 더욱 자세 한 정보는 확인해 보길 바란다.
Paper page - Qwen3-ASR Technical Report
Join the discussion on this paper page
huggingface.co