

1. R-CNN
동작방식
1. Selective Search를 이용해 2000개의 ROI(Region of Interest)를 추출한다. ( on CPU ) == Region Proposal
2. 각 ROI에 대하여 warping을 수행하여 동일한 크기의 입력 이미지로 변경한다.
3. Warped image를 CNN에 넣어서 이미지 feature를 추출한다. == (pre-trained) CNN
4. 해당 feature를 SVM에 넣어 class의 분류 결과를 얻는다.(binary SVM Classifier [Yes / No] 모델 사용) == SVM
5. 해당 feature를 Regressor에 넣어 위치(bounding box)를 예측한다. ==Bounding Box Regression
한계
1. 입력 이미지에 대해서 CPU 기반의 Selective Search를 진행해야하므로 많은 시간이 소요된다.
2.전체 아키텍처에서 SVM, Regressor 모듈이 CNN과 분리되어어서. 따라서 SVM과 Regressor의 결과를 통해서 CNN을 업데이트 할 수 없다 == End-to-End 방식으로 학습할 수가 없다.
(CNN의 softmax보다 svm이 성능이 더 좋았기 때문에 cnn에서 쭉 진행시키지 않고 네트워크를 따로 구성하였다고 함)
3. 모든 ROI를 CNN에 넣고 학습해야하기 때문에 ROI의 개수만큼 즉, 본 논문에선 2000번의 CNN 연산이 필요하다. 따라서 이로 인해 많은 시간이 소요된다.


2. Fast R-CNN

1. Selective Search를 통해 Region Proposal을 찾는다.
2. Feature vector를 추출하기 위해서 CNN을 거침
(R-CNN과 차이점은 R-CNN은 Selective Search된 이미지를 모두 CNN network를 거쳐 시간이 많이 소비되는데, Fast R-CNN은 단 한 번만 거치면서 기존보다 빠름.
3. ROI pooling을 통해 각각의 Region에 대해서 Feature에 대한 정보를 추출
4. Softmax layer를 거쳐서 각각의 class에 대한 확률 값을 구하고 이를 이용해 classification을 이뤄낸다.

2-1. ROI Pooling
classification을 할 때, FC(Fully Connected) layer를 이용해야되기 때문에 Fully connected layer의 입력으로 고정된 크기가 들어갈 수 있도록 설정해준다. 그래서 항상 고정된 크기의 feature vector를 뽑기 위해서 각 ROI 영역에 대하여 Max Pooling을 진행한다.
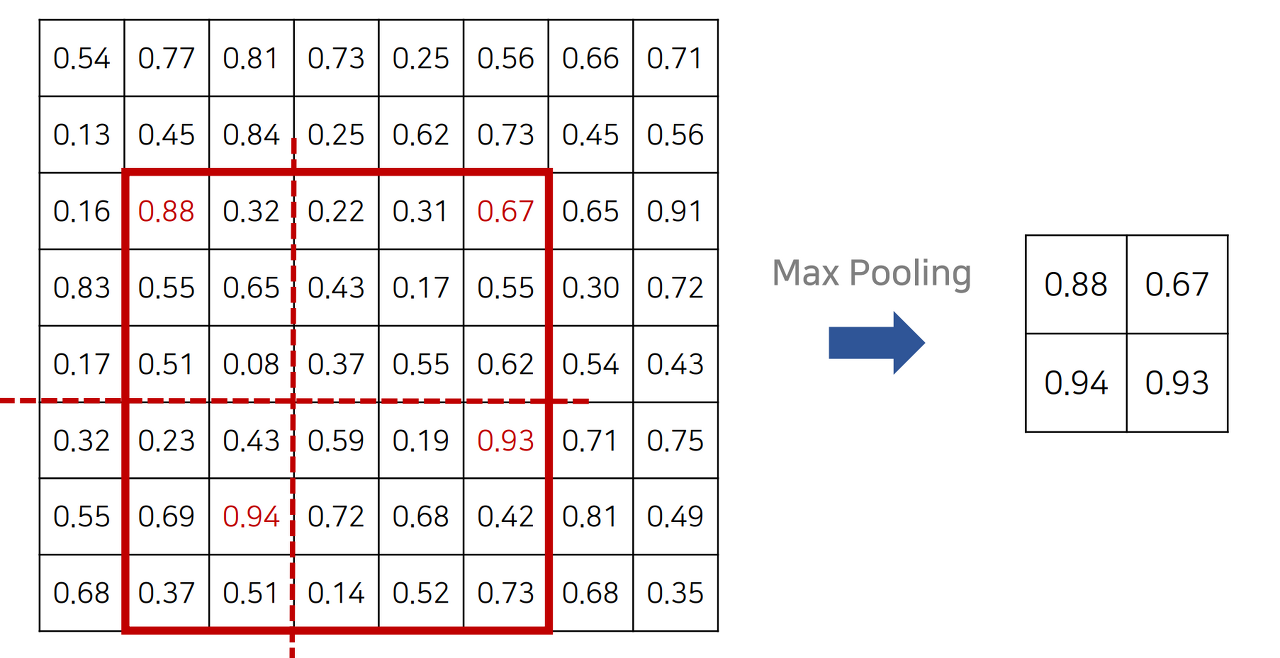
2x2의 feature vector를 추출한다고 하면 특정한 크기의 ROI 부분이 2x2로 나눠질 수 있게 만든다.
전체 activation 영역이 최대한 같은 비율로 나눠질 수 있게 만든다. 그리고 이 영역에 대해서 Max Pooling을 진행한다.
하지만 Fast RCNN은 물체가 있을법한 위치를 찾기 위해 CPU를 활용하기 때문에 느리다.(Selective Search)
3. Faster R-CNN

기존의 RCNN과 Fast-RCNN은 Selective Search과정이 모두 cpu내에서 이뤄지기 때문에 속도가 느림
Faster RCNN은 GPU상에서 연산을 하는 Region Proposal Network(RPN)을 제안.
- Feature map을 보고 어느 곳에 물체가 있을지 예측하여 Selective Search의 시간적인 단점을 해결
RPN을 통해 한 번의 forwarding을 수행하면서 어느 곳에 물체가 있을 법 한지 예측이 가기 때문에 더 빠르고 정확하게 모델이 동작함.
이후 Fast R-CNN과 동일하게 Softmax 함수를 사용 및 classification 진행.
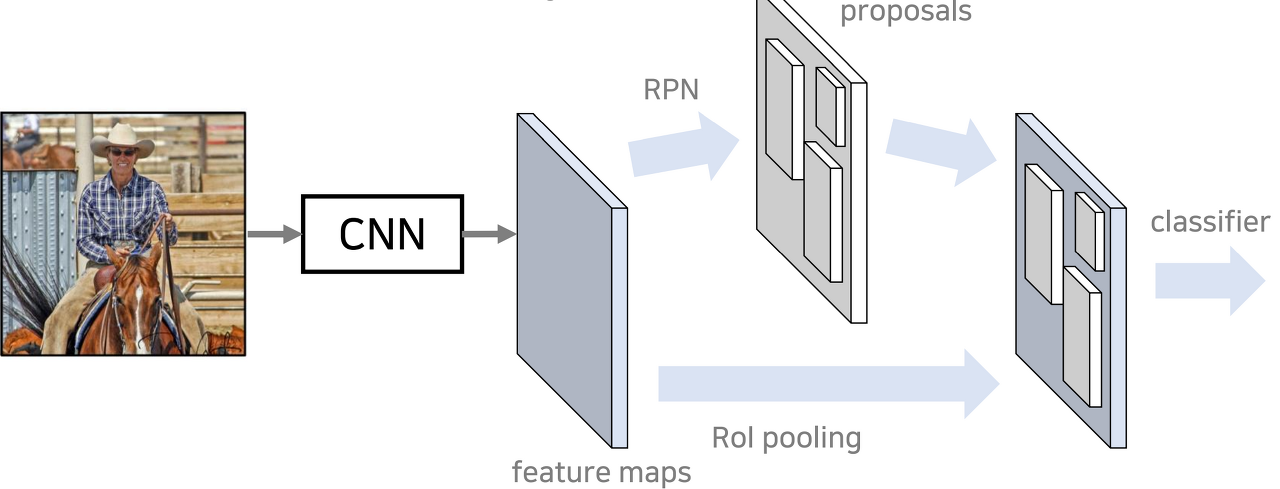
1.VGGNet 기반의 CNN으로 이미지에서 feature map을 추출한다.
2. feature map을 기반으로 RPN 을 통해 물체가 있을 법한 위치(region proposals)를 찾아낸다.
3. RPN에서 탐지한 위치 정보를 중심으로 Classification 과 Regression을 진행한다.

3-1. RPN
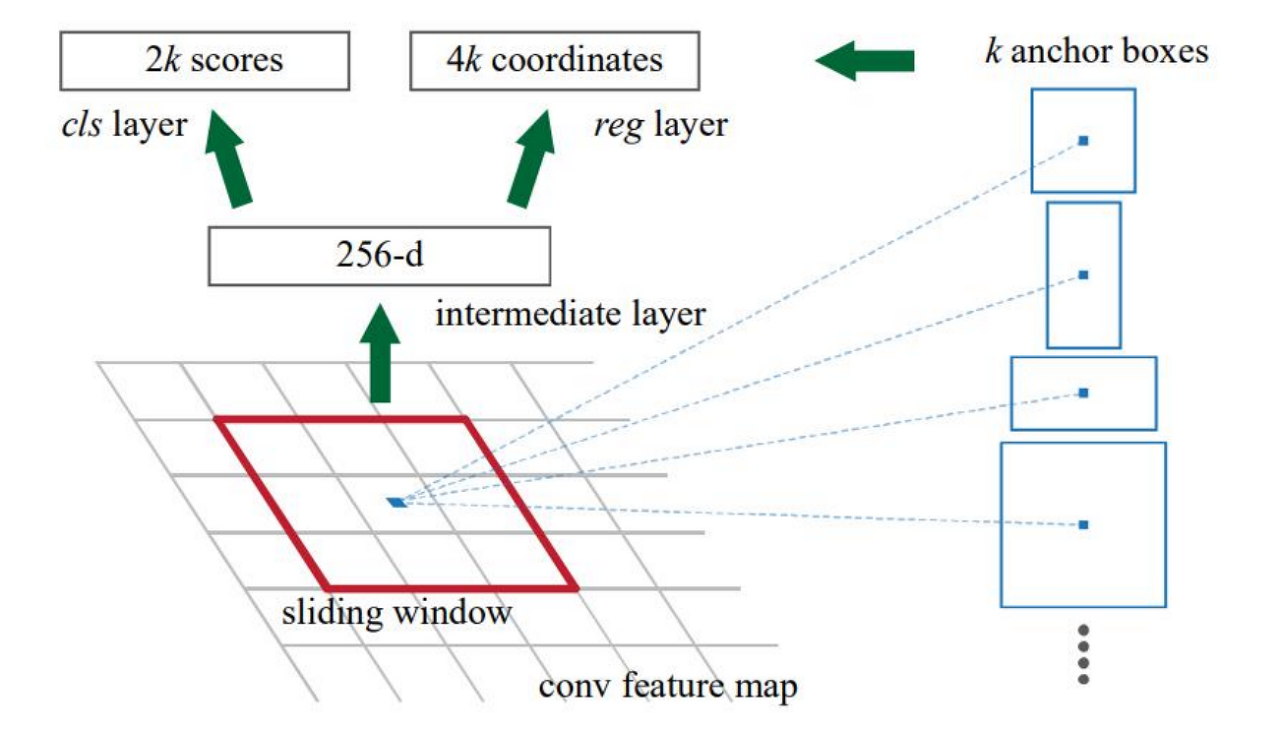
RPN은 feature map이 주어졌을 때 물체가 있을 법한 위치를 예측하는 것이다.
다양한 객체를 인식할 수 있도록 다양한 크기의 k개의 anchor box를 이용.
기본적으로 Feature map 상에서 왼쪽에서 오른쪽으로 sliding window를 적용.
sliding window를 적용하면서 각 위치마다 intermediate feature vector를 뽑고, 여기서 추출된 vector로 regression과 classification을 진행.
이 RPN에서의 classification은 물체가 있는지 없는지의 여부만 따져서 binary classification 그리고 regression은 bounding box의 위치(center_x,center_y, width,height)를 예측해준다.
4. 비교
| RCNN | 장점 | CNN을 이용해 각 Region의 클래스를 분류할 수 있다. |
| 단점 | 전체 framework를 End-to-End 방식으로 학습할 수 없다.Global Optimal Solution을 찾을 수 없다. | |
| Fast RCNN | 장점 | Feature Extraction, ROI poolingm Region Classification,Bouding Box Regression 단계를 모두 End-to-End로 묶어서 학습될 수 있다. |
| 단점 | 여전히 첫번째 Selective Search는 CPU에서 수행되므로 속도가 느리다. | |
| Faster RCNN | 장점 | RPN을 제안하여, 전체 프레임워크를 End-to-End로 학습할 수 있다. |
| 단점 | 여전히 많은 컴포넌트로 구성되며, Region Classification 단계에서 각 특징 벡터(feature vector)는 개별적으로 FC layer로 Forward 된다 |
5. Reference
R-CNN 을 알아보자
딥러닝(CNN)을 Object Detection 분야에 최초로 적용시킨 모델이며 이전의 Object Detection 모델에서 성능을 상당히 향상시키고, 이후 Fast R-CNN, Faster R-CNN, Mask R-CNN을 나오게 한 의미있는 모델인 R-CNN에 대
velog.io
Object Detection 정리(RCNN, FastRNN,FasterRCNN 중심으로)
전체적인 글 내용은 나동빈님의 유튜브를 참고하였습니다.(대신 홍보해요! 구독과 좋아요 눌러주세요..ㅎㅎ) https://www.youtube.com/watch?v=jqNCdjOB15s&t=865s ## Object Detection 개념 Object Detection은 다수의 사
bigdata-analyst.tistory.com
[Object Detection] Faster R-CNN (NIPS2016) 엄밀한 리뷰
안녕하세요! pulluper입니다 😀😀😀 이번 포스팅은 드디어 Faster RCNN을 분석을 해 보려 합니다. Faster RCNN은 2016년 NIPS 에 발표되었으며, 그 이후로도 2-stage object detection의 대표로 계속해서 사용되
csm-kr.tistory.com
Faster R-CNN 논문 리뷰 및 코드 구현
논문 제목: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Faster R-CNN 개요 SPPnet과 Fast R-CNN은 region proposal computation
velog.io
'ML & DL > Computer vision' 카테고리의 다른 글
| YOLO: You Only Look Once (0) | 2023.10.26 |
|---|---|
| SSD(Single Shot MultiBox Detector) (0) | 2023.10.26 |
| NAS(Neural Architecture Search) (0) | 2023.10.26 |
| ResNet (0) | 2023.10.26 |
| Object detection(= Classification+Localization) (0) | 2023.10.26 |