
0. YOLO
SSD 이전에 나온 1-stage detector로 unified, simple, real-time object detection이라고 부르기도 한다.
YOLO의 특징은 이미지 전체를 한 번만 보고, 통합된 네트워크를 사용하여 간편하고 빠르며 거의 실시간 객체 검출이 가능하다.

1. Grid Image
YOLO는 우선 이미지를 SxS 크기의 grid로 나눈다.
다음으로 객체의 중심이 특정 grid cell에 위치한다면, 해당 grid cell은 그 객체를 detect 하도록 할당된다.
이 선택된 셀은 Bounding Box와 Confidence, Class probability map을 예측하는데 사용된다.
2. Backbone
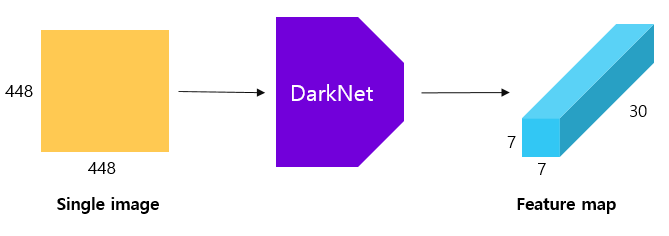

앞서 하나의 이미지를 SxS의 그리드로 나눈뒤 해당 이미지는 YOLO의 네트워크에 들어가게 된다.
YOLO는 하나의 CNN 네트워크 구조(VGG네트워크를 변형하여 저자가 만든 DarkNet)로 이루어져 있고 하나의 이미지를 넣어주면 모든 SxS의 그리드 셀에 대한 결과를 한 번에 출력하기 때문에 속도가 빠르다. 논문에서는 그리드의 크기 S=7로 설정하였다.
그림을 보면 모델의 최종 출력은 7x7x30 크기의 tensor로 반환되는데, 7x7은 그리드를 의미하며, 30은 각 그리드 셀마다의 바운딩 박스(4*2)+클래스(20)+confidence score(2)로 구성된다.
여기서 반환되는 값들에 대하여 자세히 알아보자.
2-1. Output
2-1-1. Bounding Box, Confidence Score
YOLO는 하나의 이미지의 각 그리드마다 B개의 Bounding Box를 예측한다.
각 셀은 여러 Bounding Box를 나타낼 수 있으며 해당 Bounding Box의 Confidence score을 계산한다.
논문에서는 B=2로 총 2개의 Bounding Box를 그렸으며 따라서 하나의 이미지에 총 7x7x2개의 Bounding box가 그려진다.

위의 그림을 보면 쉽게 이해할 수 있는데,
우선 하나의 Bbox에 대한 confidence score을 나타내는 $p_c$와 Bbox의 중심점 $b_x,b_y$, 높이와 너비$b_ h,b_w$가 포함된다. 즉 하나의 Bbox에 대하여 다음과 같은 tensor $[p_c b_x b_y b_h b_w]$ 를 의미한다.
이때 confidence score $P_C$는 Pr(Object)∗IoU(truth pred)로 정의되기 때문에 만약 grid cell 내에 객체가 존재하지 않는다면 confidence score는 0이 되고, 반대로 grid cell 내에 객체가 존재한다면 confidence score는 IoU 값과 같아진다
2-1-2. Class Probability Map

다음으로 각 grid cell은 C개의 conditional class probabilities인 $P(Class_i|Object)를 예측한다.
이는 특정 grid cell에 객체가 존재한다고 가정했을 때, 특정 class i일 확률인 조건부 확률값으로 예측하게 된다.
YOLO에서는 Pascal 데이터셋을 이용했기 때문에 class를 총 20개로 분류하였고, 해당 Class Probability Map의 결과 또한 7x7x20으로 나오게 된다.
2-1-3. Result

네트워크는 위의 두 가지가 모두 거쳐서 나오기 때문에 총 7x7x30의 output이 나오게 되는 것이다.
3. LOSS

S : grid 크기
B : bounding box 개수
YOLO에서는 각 Bbox에 대한 위치와 confidence loss를 계산하고 각 셀별 class 분류에 대한 loss를 계산한다.
이때 Regressin loss에서 각 셀별로 B개의 BoundingBox에 대한 모든 loss를 계산하는 것이 아닌 ground truth와 가장 유사한 Bbox에 대한 loss만 계산하게 된다.
다음 Confidence score은 객체가 있을 경우와 없을 경우를 나누어서 계산하게 되며 이 또한 모든 Bbox에 대하여 계산하는 것이 아닌 가장 유사한 Bbox에 대해서만 계산한다.
마지막으로 Classification loss도 각셀에 대하여 계산하게 된다.
4. Inference

마지막으로 각 그리드의 Bbox의 confidence score과 class 확률 (20개)를 곱해준다.
이런 과정을 거치게 되면 하나의 이미지에 대하여 매우 많은 Bounding Box가 생기게 되고 최종적으로 NMS를 이용하여 가장 정확한 Bbox만 남기게 된다.

5. summary
YOLO는 1-Stage Detector로 빠른속도를 보였으며, slidinge window나 region proposal 기반의 다른 모델과 달리 전체 이미지를 통해 학습시킴에 따라 맥락정보를 학습하여 배경 영역을 객체로, 인식하는 오류가 Fast R-CNN보다 적다고 한다.
또한 새로운 도메인이나 예상치 못한 이미지에 대해서도 상대적으로 잘 탐지해 낸다.
그러나 하나의 그리드 별로 한 객체만을 탐지하기 때문에 한 그리드에 여러 객체가 있을 경우에는 탐지하지 못하며
object가 크면 bbox 간의 IOU값의 차이가 크기 때문에 적절한 BBOX를 선정하지만, Object가 작을 경우 bbox간의 IOU차이가 근소하게 다르기 때문에 정확하지 않다는 한계가 있다.




Reference
-가장 도움 됐던 블로그
[Object detection] YOLO (you only look once) : Real-Time Object Detection (feat. 동작원리)
지난 시간까지 2 stage detector계열에 대해 알아봤는데 이번시간에는 1 stage detector의 시초인 YOLO에 대해 알아보려고 한다. 📍YOLO (you only look once)의 등장 YOLO는 조셉 레드몬에 의해 2015년 등장하였다.
dotiromoook.tistory.com
[Object Detection(객체 검출)] YOLO v1 : You Only Look Once
지난시간에 Object Detection 이란 무엇인지 간단히 알아보고, 주요 용어들에 대해 알아보았다. 2022.03.31 - [AI/Object Detection] - Object Detection이란? Object Detection 용어정리 Object Detection이란? Object Detection 용
leedakyeong.tistory.com
YOLO(You Only Look Once)란?
☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다. ☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습니다. Y
ctkim.tistory.com
[Object Detection] You Only Look Once: Unified, Real-Time Object Detection : YOLO v1 논문 리뷰
투빅스 14기 서아라
velog.io
YOLO v1 논문(You Only Look Once:Unified, Real-Time Object Detection) 리뷰
이번 포스팅에서는 YOLO v1 논문(You Only Look Once:Unified, Real-Time Object Detection) 논문을 리뷰해보도록 하겠습니다. 2-stage detector는 localization과 classification을 수행하는 network 혹은 컴포넌트가 분리되어
herbwood.tistory.com
갈아먹는 Object Detection [5] Yolo: You Only Look Once
지난 글 갈아먹는 Object Detection [1] R-CNN 갈아먹는 Object Detection [2] Spatial Pyramid Pooling Network 갈아먹는 Object Detection [3] Fast R-CNN 갈아먹는 Object Detection [4] Faster R-CNN 들어가며 오늘 리뷰할 논문은 real ti
blog.firstpenguine.school
YOLO, Object Detection Network
You Only Look Once : Unified, Real-Time Object Detection Joseph Redmon - University...
blog.naver.com
YOLO(You Only Look Once)란?
☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다. ☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습니다. Y
ctkim.tistory.com
'ML & DL > Computer vision' 카테고리의 다른 글
| Image segmentation(recognition+localization) (0) | 2023.10.26 |
|---|---|
| EfficientDet (0) | 2023.10.26 |
| SSD(Single Shot MultiBox Detector) (0) | 2023.10.26 |
| R-CNN, Fast R-CNN, Faster R-CNN (0) | 2023.10.26 |
| NAS(Neural Architecture Search) (0) | 2023.10.26 |