
내 다른 프로젝트인 수위 예측 프로젝트를 1년동안 질질 끌면서 온갖 다양한 걸 써봐서 머신러닝에 대해선 뭐 대충 잘 안다고 생각했었는데, 강사님이랑 같이 새로운 프로젝트에 대해서 간단하게나마 해보면서 부족한 걸 배웠던 것 같다.
!!! 이번 실습은 단순 실습용어서 다양한 EDA 및 feature engineering을 진행하지는 않고 강의에서 배운 optuna와 kfold를 사용한 baseline 코드 만들기 실습정도로 봐주면 될 것 같다. (사실상 구어체로 작성하듯이 해서 회고와 가깝다 내 느낀점)
데이콘 전력사용량 예측 AI 경진대회
오늘은 패스트캠퍼스 부트캠프를 진행하면서 실습한 데이콘의 2023 전력사용량 예측 AI 경진대회에 대해서 간단하게 작성해보고자 한다. 이 대회는 재작년에도 열렸던 것 같은데 또 열린 것 같다.
2023 전력사용량 예측 AI 경진대회 - DACON
분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다.
dacon.io
대회목적은 건물정보, 시간 정보, 기상정보등을 이용하여 특정 시점의 전력 사용량을 예측하는 것이다.
대회에서 제공되는 데이터는 train, test, building_info, sample_submission으로 총 4개의 데이터가 제공됐다.
// 출처: 데이콘
Dataset Info.
1. train.csv
train 데이터 : 100개 건물들의 2022년 06월 01일부터 2022년 08월 24일까지의 데이터
일시별 기온, 강수량, 풍속, 습도, 일조, 일사 정보 포함
전력사용량(kWh) 포함
2. test.csv
test 데이터 : 100개 건물들의 2022년 08월 25일부터 2022년 08월 31일까지의 데이터
일시별 기온, 강수량, 풍속, 습도의 예보 정보
3. building_info.csv
100개 건물 정보
건물 번호, 건물 유형, 연면적, 냉방 면적, 태양광 용량, ESS 저장 용량, PCS 용량
4. sample_submission.csv
100개 건물들의 2022년 08월 25일부터 2022년 08월 31일까지의 전력사용량(kWh)을 예측
num_date_time은 건물번호와 시간으로 구성된 ID
해당 ID에 맞춰 전력사용량 예측값을 answer 컬럼에 기입해야 함EDA 및 전처리
우선 EDA부터 진행하였다. 데이터의 특이한점이 있었는데, train과 test의 column이 달랐다.데이콘의 토론게시판 글도 보고 찾아보고도 했지만, 의도적인 것인지 아니면 실수인지는 잘 모르겠다. 다만 작년 대회와는 컬럼이 달라서 실수인 것 같기도 하다. 이 대회의 규칙상 외부데이터 사용이 불가능했기 때문에 test 데이터 의 일조와 일사를 구할 방법이 없었다. 결측치가 있는 것이 아니라 컬럼자체가 없고 다른 컬럼들을 이용하여 만들 수 있는 파생변수도 아니기 때문에 과감하게 drop해줬다.
train = train.drop(columns=['일조(hr)', '일사(MJ/m2)'])또한 한글로 되어있는 컬럼이 불편해서 우선 영어로 모두 바꿔주고 작업을 진행하였다.
train.columns = ['num_date_time', 'num', 'date_time', 'temperature', 'precipitation','windspeed', 'humidity', 'target']
test.columns = ['num_date_time', 'num', 'date_time', 'temperature', 'precipitation','windspeed', 'humidity']
building_info.columns = ['num', 'type', 'area', 'cooling_area', 'solar', 'ESS', 'PCS']
building_info 데이터
building_info에는 각 건물별 유형과 건물번호 그리고 건물별 정보(냉방면적, 태양광용량, ESS저장용량, PCS저장용량)이 있었다. 건물별로 전력 사용량이 다를 것이라 예측되기 때문에(나중에 보니 실제로 매우 영향이 큼) 이러한 건물 정보도 중요할 것 같았다.
예를들어 백화점, 아울렛 등은 특정 날짜에는 휴무여야 하고, 대학교도 특정 시간에 사용이 많을 것이며 이러이러한 특징들이 뚜렷할 것 같았다. (데이콘의 코드 공유에 가보면 다양한 EDA분석들이 있는데, 건물들별로 특징들이 뚜렷하게 보인다. 본 글에서는 따로 다루지 않았다.)
따라서 train, test 그리고 building_info 데이터에 빌딩번호가 공통으로 포함되어 있기 때문에, 빌딩번호를 기준으로 데이터를 합쳐줬다.
train = pd.merge(train, building_info, on='num', how='inner')
test = pd.merge(test, building_info, on='num', how='inner')train / test 데이터
train.columns
>> Index(['num_date_time', '건물번호', '일시', '기온(C)', '강수량(mm)', '풍속(m/s)', '습도(%)',
'일조(hr)', '일사(MJ/m2)', '전력소비량(kWh)'],dtype='object')
test.columns
>> Index(['num_date_time', '건물번호', '일시', '기온(C)', '강수량(mm)', '풍속(m/s)', '습도(%)'], dtype='object')위에서 볼 수 있듯이, train에는 test에 없는 일조와 일사 데이터가 있었다.
뭔가 아직 자세히 살펴보지는 않았지만, 일조와 일사 라는 단어만 들었을 때는 전력사용량과 매우 관련있어 보였다.
우선 기상데이터의 경우 강수량, 풍속, 습도에 결측치가 존재하였다.
강수량의 경우 nan으로 되어있는 것은 아마 0일 것이라 추측하여(대부분의 강수량 자료들이 비가 오지 않은 것을 nan으로 기록) 0으로 채워주고, 풍속과 습도의 경우 선형보간법을 이용하여 채워줬다.
train['precipitation'].fillna(0,inplace=True)
train['windspeed'].interpolate(method='linear',inplace=True)
train['humidity'].interpolate(method='linear',inplace=True)
test['precipitation'].fillna(0,inplace=True)
test['windspeed'].interpolate(method='linear',inplace=True)
test['humidity'].interpolate(method='linear',inplace=True)
그리고 이후 모델을 사용하기 위해서 미리 categorical 변수인 건물타입을 원-핫 인코딩을 이용하여 처리해줬다.
train=pd.get_dummies(data=train,columns=['type'])
test=pd.get_dummies(data=test,columns=['type'])클러스터링
대회참가자들의 토론이나, 코드 공유들을 참고하면서 크게 3가지 정도의 방법을 생각해봤다.
우선 이 방법을 생각하기 위해서는 앞서서 다양한 EDA를 해봤어야 한다. (본 글에서는 제대로된 EDA를 진행하지 않았으니 다른 글들을 참고바랍니다~)
아무튼 EDA를 진행해보면, 건물별로 혹은 건물타입들, 이런 것들끼리 특정한 패턴이 있는 것을 볼 수 있었다.
상식적으로도 당연하고, 이러한 정보가 매우 중요할 것 같았다. 그래서 아까 말한 3가지가 뭐냐하면 아래와 같다.
첫째, 클러스터링을 통해서 데이터를 나누고, 각 군집별로 모델링.
둘째, 건물 타입별로 모델을 만들어서 모델링.
셋째, 건물별로 모델을 만들어서 모델링.
우선 나는 클러스터링을 이용한 방법을 사용했고, 대회에서의 1등은 건물별로 모델링한 것이고, 내 생각에 가장 좋아보이고 이상적인 것은 건물 타입별 모델링 같다.
우선 클러스터링은 건물에 대한 정보가 없거나, 마스킹 되어있을 때 더 유용할 것 같다. 이번 대회에서는 건물 번호, 건물 타입이 모두 나와있기 때문에 따로 클러스터링 보다는 타입별, 건물별 모델링이 더 성능은 좋게 나올 것 같긴하다.
다만 건물별은 우선 본 데이터에서는 건물이 총 100개이기 때문에 모델을 100개를 만들어야 하는데, 이건 train 데이터와 test 데이터의 건물 종류가 다르면 사실상 의미가 없어지기 때문에 그렇게 좋다고는 생각하지 않았다.(물론 이번 대회에서는 동일하지만, 실제 사회에서 새로운 건물에 대한 전력을 예측하는 것이 불가능해진다.) 그리고 건물별로 진행하게 되면 각 모델이 학습하는 데이터 자체가 적어지기 때문에 과적합이 일어날 것이라고 생각했다.
따라서 나는 만약 한다면 건물 타입별로 하는 것이 그나마 낫다고 생각했다.
--> 아무튼 이거는 음..솔직히 이 세가지 방법 아니 건물별, 건물 타입별 모델링의 경우 방법보다는 파라미터 튜닝이나 전처리, 피쳐엔지니어링에 의한 차이라고 본다.(내 생각엔 건물타입이 젤 좋을 듯 실생활에 대입하기에)
본 글에서는 클러스터링을 이용한 방법만 다루겠다.
우선 클러스터링에 대한 간단한 설명은 아래를 읽고오면 될 것 같다.
K-means 알고리즘
K-means는 Clustering(군집화)를 수행하는 알고리즘이며, 이때 clustering이란 비슷한 데이터를 그룹으로 묶는 방법을 의미한다. k-means는 가장 대표적인 클러스터링 알고리즘으로 각 클러스터와의 거리
changsroad.tistory.com
이 kmeans를 이용하여 클러스터링을 진행하였고,
kmeans와 timeseries kmeans 두개를 모두 진행해봤는데, timeseries kmeans가 더 적절하다고 판단되어 사용하였다. 이후 elbow method를 이용해서 군집의 개수를 3개로 정하고 이 3개의 군집별로 모델을 만들고자하였다.
def clustering(type='kmeans',data=train):
feature_matrix = pd.DataFrame()
for n in range(1, 101):
bn = data.loc[data.num == n, 'target'].values
feature_matrix[n] = bn
temp = StandardScaler().fit_transform(feature_matrix)
feature_matrix = pd.DataFrame(data=temp, columns=list(range(1, 101))).T
K_range = range(2, 20)
inertias,labels = [],[]
if(type=='ts_kmeans'):
cl_model = TimeSeriesKMeans(n_init=15,max_iter=200, metric="euclidean", random_state=624,n_jobs=-1)
else:
cl_model=KMeans(init='k-means++',n_init='auto',random_state=624)
for K in tqdm(K_range):
cl_model.set_params(n_clusters=K)
cl_model.fit(feature_matrix)
inertias.append(cl_model.inertia_)
labels.append(cl_model.predict(feature_matrix))
plt.figure(figsize=(6, 6))
plt.plot(range(2,20), inertias)
plt.xticks(range(2,20))
plt.show();
return labels
이제부터 좀 내가 강의를 들으면서 배운점이 나온다.
1. 클러스터링을 할 때 반드시 시드를 고정하자.
: 이건 원래 모델링을 할때나 뭐든 random 요소등을 이용할 때 파라미터중에 random_state가 있는데, 이걸 고정해야했다.
지금까지는 매번 흘려들었었는데, 이번에 실습하면서 이거땜에 낭패를 볼 뻔했다. 우선 이따가 나올 떄 설명하겠다.
모델 학습 및 파라미터 튜닝
사실 이 부분이 이번 실습을 한 목적?이면서 내가 모르던걸 배운 부분이었다.
모델링을 하면서 다양한 모델들을 배우고 모델등을 갖다 쓰는 건 매우 쉽다. 그리고 요즘에는 pycaret, autogluon? 등의 다양한 automl 등도 있어서 모델에 대해 자세하게 알지 못해도 할 수 있다고 생각 했.었.다.
그래서 지금까지 다른 프로젝트를 진행할 때 eda, 전처리, 좋은 모델 고르기 에만 집중한뒤 걍 optuna나 gridsearch는 인터넷에서 대충 양식 긁어가지고 iteration만 크게 하고 기다렸었다.
그런데 optuna를 사용할 때도 각 데이터마다 다른 설정등을 사용해야한다는 것을 알게되었다.
평가지표
smape는 회귀모델에서 사용하는 평가지표로 Symmetric Absolute Percentage Error이다. 이는 MAPE가 가진 한계점을 보완하기 위하여 만들어진 평가지표인데, MAPE는 오차를 실제값으로 나누는데 반면, SMAPE는 실제 값과 에측값의 평균으로 나누어서 구한다. 이 SMAPE는 작을수록 모델의 성능이 좋다.
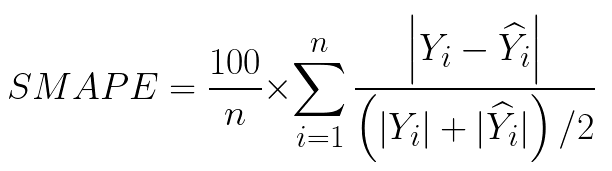
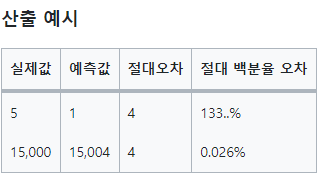
이러한 SMAPE를 사용하면 아래와 같이 비율로써 성능을 비교할 수 있다. 둘은 같은 절대오차를 가지고있지만, 숫자의 크기가 다르기 때문에 아래가 더 오차가 적다고 보는 것이 일반적인 회귀에서는 맞다.
- SMAPE의 장점
1. 0~200% 사이의 확률 값을 가지기 때문에 결과 해석이 용이함
2. 데이터 값의 크기와 관련된 것이 아닌 비율과 관련된 값을 가지기 때문에 다양한 모델, 데이터의 성능 비교에 용이함
3. MAPE와는 다르게 실제 정답 값에 0이 존재해도 계산이 가능함
- SMAPE의 단점
1. 실제 정답 값과 예측 값이 모두 0일 경우 SMAPE 계산이 불가능 함
2. 예측 값이 실제 정답 값보다 작을 때 분모가 더 작아지기 때문에 계산되는 오차가 커지는 현상이 발생함
3. 실제 정답 값 또는 예측 값이 0인 경우 자동적으로 SMAPE값의 크기가 최대로 도출됨
def smape(a, f):
return 1/len(a) * np.sum(2 * np.abs(f-a) / (np.abs(a) + np.abs(f))*100)모델
모델은 데이터의 개수도 충분하기 때문에, LGBM을 사용하였다.
우선 LGBM을 이용하여 각 클러스터별로 기본적인 모델링을 먼저 실시하였다.
이 때 이제 깨달았던 것이, 2가지가 있었다. 우선 파라미터이다. 우선 lgbm는 파라미터에 따라 성능이 매우 좌우되기 때문에 파라미터 설정이 중요하다. 따라서 huristic(노가다)방법으로 파라미터를 찾아서 적용했었는데 이때 이 파라미터를 모든 클러스터에 적용하면 안됐다. 무슨 말이냐 하면 각 클러스터별로 데이터의 개수가 똑같으면 상관없을 테지만 클러스터별로 데이터의 개수가 다르기 때문에 같은 하이퍼파라미터를 사용하는것이 적절치 않다는 것이다. 과적합과 관련된 문제 때문에 하이퍼 파라미터에는 데이터의 개수와 연관된 것들이 많기 때문에 각 클러스터별로 다른 하이퍼 파라미터를 적용하여 valdaion set에 대하여 성능을 평가하였다.
def split_data(cluster_num):
X = train[train.cluster == cluster_num].drop(columns=['num_date_time', 'date_time', 'target', 'cluster'])
y = train[train.cluster == cluster_num].target
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.05, random_state=624)
print(X_train.shape, y_train.shape, X_val.shape, y_val.shape)
return X_train, X_val, y_train, y_val
def train_evaluate(cluster_num,params_list,X_train, X_val, y_train, y_val):
params=params_list[cluster_num]
model = LGBMRegressor(**params,verbose=-1)
model.fit(X_train,y_train)
y_pred_train= model.predict(X_train)
y_pred_val = model.predict(X_val)
train_score = smape(y_train, y_pred_train)
val_score = smape(y_val, y_pred_val)
print("Base train Score : %.4f" % train_score)
print("Base validation Score : %.4f" % val_score)
return model
params_cluster0={
"num_leaves" : 1023,
"max_depth" : 10,
"learning_rate" : 0.23,
"n_estimators": 50,
"min_child_samples" :10,
"reg_lambda" : 7,
"colsample_bytree" : 0.5,
"device":'gpu',
'random_state':624
}
params_cluster1={
"num_leaves" : 1023,
"max_depth" : 10,
"learning_rate" : 0.2,
"n_estimators": 50,
"min_child_samples" :10,
"reg_lambda" : 5,
"colsample_bytree" : 0.5,
"device":'gpu',
'random_state':624
}
params_cluster2={
"num_leaves" : 255,
"max_depth" : 12,
"learning_rate" : 0.3,
"n_estimators": 100,
"min_child_samples" :20,
"reg_lambda" : 5,
"colsample_bytree" : 0.5,
"device":'gpu',
'random_state':624
}
params_list= [params_cluster0,params_cluster1,params_cluster2]
두번째로 중요했던 것이 random state이다. 위와 같이 클러스터별로 각기 다른 파라미터를 적용해야겠다고 생각한 뒤, 강사님과 동일한 파라미터로 진행을 했는데 성능이 극심하게 차이가 났다. 그래서 왜그럴까 코드에는 문제가 없는데라고 생각을 했었다. 그러다가 알아낸 것이 클러스터가 나눠진 것에 따라 각 클러스터의 크기를 보고 파라미터를 설정했었는데 kmeans를 할 때 random_state를 설정을 안해더니 클러스터링 할 때마다 각 클러스터의 데이터의 개수, 클러스터 번호 순서가 바뀌었던 것이다...이것떔에 하이퍼파라미터가 내가 원하는 클러스터에 적용이 되지않았고 이에 과적합 혹은 과소적합이 되었던 것이다..이후로는 kmeans에도 random_state를 설정하고 다시 진행하였다.
파라미터 튜닝
다음으로 파라미터 튜닝이다. 파라미터 튜닝은 optuna를 이용하였다. 기존에도 optuna를 이용했었는데 사실 잘 모르고 그냥 다른 예제들의 파라미터 세팅(search space)를 사용했었다., 그런데 이것도 위에서 설명했듯이 데이터마다 크기, 특징이 다르기 때문에 다른 파라미터 범위를 지정해야했다.
그래서 이것도 위와 같이 각 클러스터별로 다른 search space를 설정하여 튜닝을 진행하였다. (추가적으로 optuna dashboard를 이용해서 다양한 파라미터 search space를 실험해봤다.)
def objective(trial, X, y, K,params):
params_optuna={
"num_leaves" : trial.suggest_categorical('num_leaves',params['num_leaves']),
"max_depth" : trial.suggest_int('max_depth',params['max_depth'][0],params['max_depth'][1]),
"learning_rate" : trial.suggest_float('learning_rate',params['learning_rate'][0],params['learning_rate'][1]),
"n_estimators": trial.suggest_int('n_estimators',params['n_estimators'][0],params['n_estimators'][1]),
"min_child_samples" : trial.suggest_int('min_child_samples',params['min_child_samples'][0],params['min_child_samples'][1]),
"reg_lambda" : trial.suggest_float('reg_lambda',params['reg_lambda'][0],params['reg_lambda'][1]),
"colsample_bytree" : trial.suggest_categorical('colsample_bytree',params['colsample_bytree']),
"device":'gpu',
}
model = LGBMRegressor(**params_optuna,verbose=-1)
folds = KFold(n_splits=K, random_state=624, shuffle=True)
losses = []
for train_idx, val_idx in folds.split(X, y):
X_train = X.iloc[train_idx, :]
y_train = y.iloc[train_idx]
X_val = X.iloc[val_idx, :]
y_val = y.iloc[val_idx]
model.fit(X_train, y_train)
preds = model.predict(X_val)
loss = smape(y_val, preds)
losses.append(loss)
return np.mean(losses)
def tune_parameter(cluster_num,optuna_params_list,X_train, y_train):
K = 5
# optuna에 인자를 넘기고 싶을 경우
opt_func = partial(objective, X=X_train, y=y_train, K=K,params=optuna_params_list[cluster_num])
K = 5
sampler = TPESampler(seed=624)
study = optuna.create_study(direction="minimize", # 최소/최대 어느 방향의 최적값을 구할 건지.
sampler=sampler,
storage="sqlite:///db.sqlite3",
study_name=f"{cluster_num}_train(23.12.01)",
load_if_exists=True)
study.optimize(opt_func, n_trials=70)
print("Tuned train Score: %.4f" % study.best_value) # best score 출력
print("Tuned params: ", study.best_trial.params) # best score일 때의 하이퍼파라미터들
return study
optuna_params_cluster0={
"num_leaves" : [2**9-1, 2**10-1, 2**11-1],
"max_depth" : (8,15),
"learning_rate" : (0.01,0.1),
"n_estimators": (50,200),
"min_child_samples" :(10,25),
"reg_lambda" : (5.0,20.0),
"colsample_bytree" : [0.5,0.7],
"device":'gpu',
}
optuna_params_cluster1={
"num_leaves" : [2**8-1, 2**9-1, 2**10-1],
"max_depth" : (10,15),
"learning_rate" : (0.01,0.1),
"n_estimators": (50,200),
"min_child_samples" :(10,25),
"reg_lambda" : (5.0,20.0),
"colsample_bytree" : [0.5,0.7],
"device":'gpu',
}
optuna_params_cluster2={
"num_leaves" : [2**5-1, 2**6-1, 2**7-1],
"max_depth" : (10,15),
"learning_rate" : (0.01,0.1),
"n_estimators": (50,200),
"min_child_samples" :(10,25),
"reg_lambda" : (5.0,20.0),
"colsample_bytree" : [0.5,0.7],
"device":'gpu',
}
optuna_params_list= [optuna_params_cluster0,optuna_params_cluster1,optuna_params_cluster2]submission 생성
이후, train셋과 동일한 전처리를 test 셋에 진행해준 뒤, 클러스터도 동일하게 설정해주고 제출을 했다.
후기
진행과정을 간단하게 확인해보자 .
1. 결측치처리, 필요없는 column drop
2. 클러스터링 진행
3. feature engineering(시간관련, 휴일관련 컬럼 추가)
4. lgbm+optuna를 이용한 train
5. submission 생성
우선 시작할 때도 말했지만, 제대로 된 eda도 진행하지 않았고, feature engineering도 간단하게 시간관련 column만 추가했다. 그래도 클러스터링(kmeans, time series kmeans)을 진행하고 kfold, optuna등을 이용하여 모델링에 관련된 것을 다양하게 진행해봤다. 이번 실습을 통해서 하이퍼파라미터의 중요성에 대하여 알게되었던 것 같다.
코드는 모두 아래 github에 포함되어있습니다.
GitHub - Bae-ChangHyun/Upstage-fastcampus
Contribute to Bae-ChangHyun/Upstage-fastcampus development by creating an account on GitHub.
github.com