
0. Clustering
클러스터링은 주어진 데이터(X)와 유사한 데이터들을 묶어주는 방법이다. 클러스터링은 비지도학습이기 때문에 y가 존재하지 않는다. 클러스터링에서 가장 중요한 것은 feature vector과 similarity이다.
Clustering(군집화) 알고리즘으로 K-means가 있다. k-means는 각 클러스터와의 거리 차이 분산을 최소화하여 데이터를 분류하는 것을 목적으로 한다. 우선 k-means의 방법을 간단하게 확인해 보자.
1. K-means



1-1. 군집의 개수(K) 설정
우선 군집의 개수 K를 설정하는 것부터 시작된다. 사실 이점은 어찌 보면 k-means의 단점이라고 볼 수 있다. 사용자가 임의로 정해줘야 하는 파라미터이기 때문이다. 하지만 추후에 이런 K를 정하는 다른 방법들이 있으니 우선 군집을 몇 개로 분류할 것인지 사용자가 정해줘 여한다고만 알고 넘어가자.

1-2. Centroid(클러스터 중심) 설정
군집의 중심이 되는 Centroid를 설정해줘야 한다. 제일 첫 번째에만 정해주면 추후에는 반복하며 중심점을 재설정하게 짜여있는데,
이러한 초기 centroid를 정하는 방법에도 여러 가지가 있다.
1) randomly search -> 랜덤으로 k개의 중심점을 정함.
2) manually assign -> 사람이 임의로 k개의 중심점을 정함.
3) k-means ++
->randomly search의 단점을 개선하기 위해 추후에 구상된 알고리즘으로, 우선 1개의 centroid를 정한 뒤 해당 centroid와 나머지 데이터포인트들과의 거리를 계산하고, 계산된 거리를 바탕으로 거리에 비례하여(가장 먼 거리에 있는) 나머지 centroid를 구하게 된다. 이러한 과정을 k번 반복하여 k개의 centroid를 설정한다.

1-3. 데이터를 군집에 할당하기
모든 데이터를 거리(유클리디안거리)가 가까운 군집으로 설정한다.

1-4. Centroid 재설정하기
각 군집에 모인 데이터들의 평균(mean)을 기반으로 중심점을 다시 정한다.
1-5. 데이터를 군집에 재할당하기
Centroid가 더 이상 변하지 않을 때까지 3번과 4번 과정을 반복한다.
1-6. 최적의 K 찾기
위에서 말했듯 k-means의 단점으로 군집의 개수 k를 사용자가 직접 지정해줘야 하는데, 이러한 k를 찾는데 도움을 주는 알고리즘들도 있다. 우선 k-means알고리즘은 클러스터 중심과 클러스터에 속한 샘플사이의 거리를 잴 수 있는데, 이 거리의 제곱 합을 `inertia`라고 부른다. 이 `inertia`는 클러스터에 속한 샘플이 얼마나 가깝게 모여있나를 나타내는데, 그렇기 때문에 클러스터의 개수가 늘어나면 클러스터 하나에 포함된 데이터의 개수가 줄어들기 때문에 이너셔도 보통 줄어든다. 이때 `elbow`기법은 이 inertia와 cluster의 개수를 비교하여 최적의 클러스터를 구하는 방법이다. 아래 그래프에서 볼 수 있듯이 클러스터 개수를 증가시킴에 따라 inertia를 계산해 보면, 그래프가 급격하게 꺾이는 부분이 있다. 이때 그 부분을 최적의 클러스터 개수라고 본다. 이 지점을 지나면 클러스터 개수를 늘려도 클러스터에 밀집된 정도=inertia가 개선되지 않으므로, 굳이 클러스터를 더 만들 필요가 없는 것이다.

1-7. K-means 장/단점
장점
- 직관적이고 구현이 쉽다: 위에 설명된 것처럼 단계별로 수행방법이 간단하며 해석이 간단하다.
- 대용량 데이터에 적용가능하다: 복잡한 계산이 필요하지 않고, 단순 거리만 계산하기 때문에 속도가 빠르다
- 수렴성이 보장된다: 어떠한 경우에도 군집을 배정하도록 되어있다.
단점
- 초기값에 민감하다: 초기 군집의 개수 혹은 군집의 중심점에 민감하다.
- 이상치에 영향을 받는다: 평균 maen을 계산하기 때문에 이상치에 민감하다.
- 그룹 내 분산구조를 반영할 수 없다: euclidean 거리를 기반으로 하기 때문에 원하는 분산구조형태로 클러스터가 구성이 안된다. 또한 데이터의 분포가 이상할 경우 잘 분류가 되지 않는다.

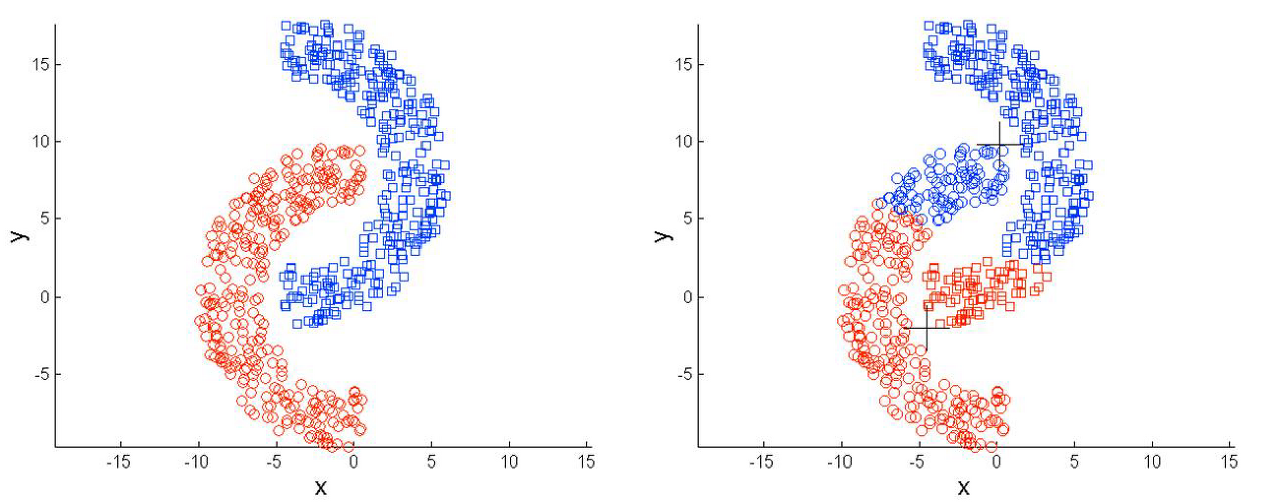
- 범주형 변수에는 적용이 불가능하다: 이 역시 euclidean 거리를 기반으로 하기 때문에 따로 처리를 진행해줘야 한다, 혹은 k-modes 알고리즘 등 다른 알고리즘을 적용해야 한다.
- 차원의 저주에 걸리기 쉽다: 속성의 개수가 많을수록 군집화의 정확도가 떨어진다.

1-8. 구현
코드의 경우 scikit-learn을 이용하여 쉽게 구현할 수 있다.
# import sci-kit learn
from sklearn.cluster import KMeans
df = np.array([[1,4],[2,2],[2,5],[3,3],[3,4],[4,7],[5,6],[6,4],[6,7],[7,6],[7,9],[8,7],[8,9],[9,4],[9,8]])
n_clusters = 3
kmeans = KMeans(n_clusters=n_clusters, init='k-means++', max_iter=300, n_init=10)
y_pred = kmeans.fit_predict(df)
> [1 1 1 1 1 0 0 0 0 0 2 2 2 0 2]위와 같이 `n_cluster`로 클러스터의 개수를 지정해 주고, 위 코드에서는 초기 centroid를 k-means++로 설정해 주었는데, random으로 설정해 줄 수도 있다. 그리고 `max_iter`을 300으로 설정하여 중심점 이동이 없으면 이전에 종료하나, 이동이 있어도 최대 300번만 수행한다. `n_init`은 서로 다른 centroid를 10번을 설정하여 가장 좋은 것을 사용하게 된다.
2. Hierachical Agglomaerative Clustering

Hierachical Agglomaerative Clustering, 상향식 계층 클러스터링은 데이터를 유사한 순서대로 묶어서 계층 구조를 만드는 방식으로 데이터를 묶어주는 방법이다. 위의 그림에서 밑에서부터 위로 점점 데이터를 묶어주는 방식으로 구성한다.
위의 그림을 Dendrogram이라고 부르며, x축은 데이터 하나하나를 의미하며, y축은 유사도를 의미한다.(일반적으로 euclidean distance).
HAC의 단점은 모든 데이터 간의 유사도를 계산해야 하기 때문에 많이 느리다는 단점이 있다.

2-1. 구성 방식
1. 모든 데이터를 각자 독립적인 클러스터로 세팅한다.
2. 유사도와 묶는 방식을 선택한다.
3. 가장 유사도가 높은 2개의 클러스터를 고른다. (맨 처음엔 데이터 2개)
4. 2번에서 정해진 방식으로 묶는다. (Single linkage의 경우 가장 가까운 데이터의 쌍이 포함된 두 개의 클러스터를 합친다)
5. 모든 데이터가 묶일 때까지 3,4번을 반복한다.(첫 번째 이후는 클러스터와 데이터, 클러스터와 클러스터 구조)
6. 최종적으로 dendrogram에서 특정 임계값을 기준으로 잘랐을 때, 나뉘는 클러스터를 최종 클러스터로 선정한다.
2-2. linkage 방식
1. single: 가장 가까운 데이터 pair가 포함된 2개의 클러스터를 합칩니다.
2. Average: 클러스터 간의 평균 거리가 가장 가까운 2개의 클러스터를 합칩니다.
3. Complete: 임의의 두 개의 클러스터중에 가장 멀리 있는 데이터 간의 거리가 가장 가까운 두 개의 클러스터를 합칩니다.
4. Ward: 모든 클러스터들 간의 within cluster variance가 최소가 되는 클러스터들을 합친다. 이때 within cluster variance란 클러스터 내부의 데이터 간의 sum of squared distance를 의미한다.
2-3. 장단점
장점
1. 원하는 유사도 계산 방식과 linkage방식을 선택할 수 있어서, 다양한 공간에서 다양한 형태의 클러스터를 찾을 수 있다.
2. dendrogram을 이용하여 데이터에 따라 유연하게 최적의 클러스터 개수를 정할 수 있다.
3. 어떤 linkage방법을 사용하더라도 한 번에 하나씩 클러스터가 줄어들기 때문에 원하는 클러스터 개수를 찾을 수도 있다.
단점
1. 시간이 매우 오래 걸리기 때문에 대용량 데이터에는 적합하지 않다.
3. DBSCAN
DBSCAN, Density Based Spatial Clustering of Applications with Noise는 정의한 밀도에 따라 인접한 데이터를 계속해서 묶어주는 방법이다.

DBSCAN은 이전 기법들과는 다르게 noise data를 outlier로 처리하여 분류한다. 따라서 outlier detection에서도 사용할 수 있다.
3-1. 구성 방식
1. 밀도를 정의하기 위한 파라미터 MinPts와 Eps를 정의한다.
-> Eps는 같은 묶음으로 판단하는 기준이 되는 거리값이다.
-> MinPts는 같은 묶음으로 판단하기 위해서 Eps를 반지름으로 하는 원을 그렸을 때 최소한으로 포함되어야 하는 데이터의 개수를 의미한다. (이를 range query를 이용해서 선택한다.)

2. 각 데이터를 기준으로 Eps 크기를 가지는 원을 그려서 그에 해당하는 데이터를 찾는다. = range query
이 결과로 Minpts 이상의 데이터가 포함되면 그 데이터를 Core point라고 지정한다.
3. Core point와 연결된 모든 Core Point들은 하나의 클러스터로 묶인다.
4. 만약 어떤 포인트가 range query를 했을 떄 MinPts를 만족하지 못하지만, 결과에 Core Point가 포함되어 있는 경우에는 해당 포인트는 Border Point가 된다. Border Point까지는 하나의 클러스토 묶인다.
5.Core Point와 Border Point에 모두 포함되지 않는 데이터를 -1 라벨을 부여밭은 outlier로 판별된다.
3-2. 장단점
장점
1. 다양한 형태의 데이터에 대해서 클러스터를 굉장히 잘 파악한다.=성능이 좋다
2. 어떻게든 다른 클러스터에 모든 데이터를 포함시키는 다른 방식들과 달리, outlier을 정의하기 때문에 만들어진 클러스터의 품질이 좋다. =특징이 뚜렷하고 밀도가 높다, 해석력이 뛰어나다.
단점
1. MinPts와 Eps을 직접 설정해줘야 한다.
2. 모든 포인트에 대해 Range Query를 계산해야 하기 때문에 느리다.
3. 고차원 공간에서 성능이 떨어지는 단점이 있다. -> 차원의 저주
eucliedan distance를 쓰기 때문에 Range Query를 계산할 때마다 겪음.
'ML & DL > 개념정리' 카테고리의 다른 글
| 분류와 회귀 (0) | 2023.12.11 |
|---|---|
| Evaluation metric (평가 지표) (1) | 2023.12.11 |
| 부스팅(Boosting) 알고리즘 (0) | 2023.11.30 |
| 머신러닝 기초 (0) | 2023.11.24 |
| 데이터사이언스 시작 (0) | 2023.11.24 |