
머신러닝
`머신러닝`: 컴퓨터가 주어진 입력값 X와 결과값 Y 사이의 관계를 찾아내는, 모델링하는 것을 의미한다.


Supervised learning(지도학습)
: 입력데이터 x와 정답데이터 y가 학습에 함께 사용되는 방법.
-> classification: 주어진 데이터 x를 몇 가지 종류로 나누는 방법
-> regression: 주어진 데이터 x와 그에 대한 정답값 y사이의 관계를 찾는 방법.
Unsupervised learning(비지도 학습)
: 입력데이터만 학습에 사용되는 방법론(정답 데이터 y가 주어지지 않음)
-> clustering: 주어진 데이터 x를 몇 가지 그룹으로 나누는 방법
-> dimensionality reduction: 주어진 데이터 x의 중요한 정보를 뽑아내는 방법
Reinforcement learning(강화학습)
:행동의 대상(agent)와 환경(environment) 사이의 interaction을 통해 보상(reward)을 최대화하는 방법.
Data Split
일반적으로 `data split`이라고하면, 전체 데이터를 train과 test 데이터로 분리하는 것을 말한다.
그러나 실제 머신러닝 문제들을 해결할 때는 train, test로 분리하는 것이 아니라 주어진 train 셋을 train과 valid 셋으로 분리하는 것이 일반적이다. 이러한 데이터 분할을 하는 목적은 train데이터를 학습시킨 모델에 test 데이터를 넣었을 때 train 데이터만큼 성능이 99% 잘 나오지 않기 때문이다. 그 이유는 과적합 때문인데, 모델이 train 셋을 전부 맞추기 위해 이에 벗어난(test 데이터)가 들어오면 성능이 낮아지는 것이다.
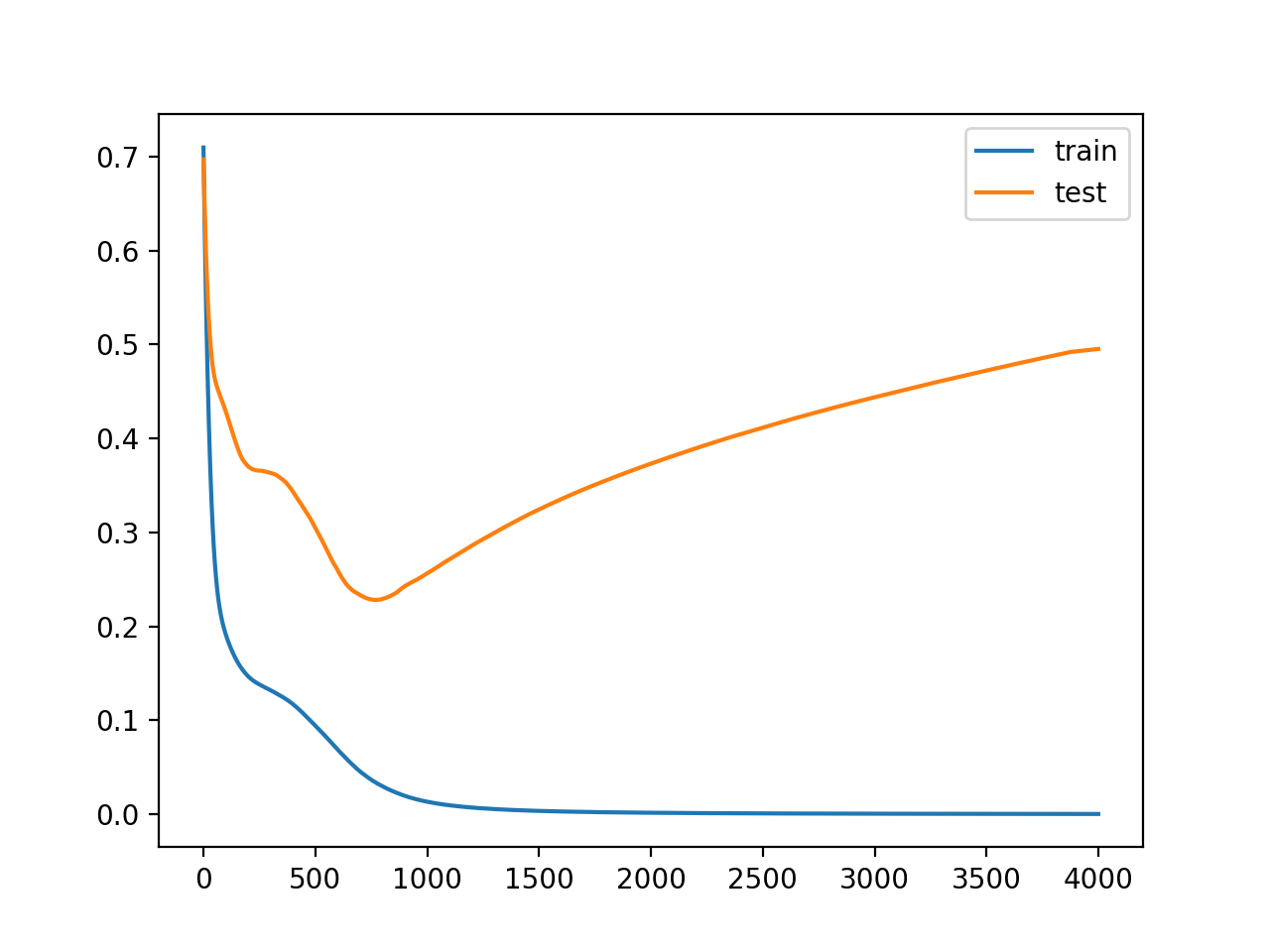
이러한 오버피팅을 방지하기 위해 주어진 train 셋을 train+valid로 나누어서 train 셋을 학습하면서 중간 과정에서 계속하여 valid 셋을 평가한다. 이때 valid 셋은 학습하지 않고 평가하는데만 사용된다. 이 valid 셋이 사실상 test 셋의 역할과 동일하고 train 셋이 아닌 처음 보는 valid 셋에 대해 성능이 높아지는 방식으로 학습하다 보면 모델이 전부 학습되었을 때 test 셋에도 잘 맞을 것이다라는 생각이다.

이러한 머신러닝의 주 목적은 한 번도 보지 못한 unseen data를 잘 예측하기 위함이기 때문에 train/test split이라고 부르지만, 사실 기존의 train과 test 데이터 셋이 존재할 때. train을 train과 validation 셋으로 나누고, train set을 학습시키고, validation으로 평가한 다음 test의 경우는 최종에 결과를 확인하는 형식으로만 사용한다. test는 절대로 학습에 관여해서는 안된다. data split을 할 때 주의할 점은 범주형 데이터의 경우 타겟의 비율을 고려하여 분할해야 하며, 모든 데이터의 전처리들은 동일해야 한다.
이러한 데이터 스플릿은 scikit learn패키지안에 쉽게 구현되어 있다.
아래와 같이 `sklearn.model_selection`으로 부터 `train_test_split`함수를 불러와주고, 그 안에 다양한 파라미터들과 우리가 분할하고자 하는 데이터의 feature을 나타내는 X와 target을 나타내는 y를 넣어주면 된다.
from sklearn.model_selection import train_test_split
X = data['data']
y = data['target']
x_train, x_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, shuffle=True, stratify=target, random_state=34)파라미터에 대하여 간단하게 설명해보겠다.
`test_size`: 이름에서 알 수 있듯이 테스트 셋 구성의 비율을 의미한다. test_size=0.2로 지정하면, 전체 데이터 셋의 20%를 test 셋으로 지정한다는 것이다.
`shuffle`: default값은 True로 지정되어 있으며 split을 하기 전 데이터를 섞을지를 제어하는 인자이다.
`stratify`: default값은 True로 분류(classification)를 해결할 때 매우 중요한 옵션인데, stratify값을 target(y)로 지정해 주면, 해당 y의 비율을 train과 test에 비율에 맞게 나눠준다. 예를 들어 target이 1 혹은 0으로 나뉘어있을 때, 전체 데이터셋 100개에서 target이 1인 게 60, 0이 40이라 하면 test_size를 0.2로 뒀을 때 test 데이터셋 20개 중 target 1인 게 60*0.2=12개 target 0인 게 8개로 나뉘어 한쪽에 target이 쏠리는 것을 방지한다.
`random_state`: 세트를 섞을 때 이 값을 고정시켜 놓고 분할해야 나중에 다시 분할할 때 고정된 데이터 셋을 얻을 수 있다.(즉 하이퍼파라미터 튜닝 등을 할 때 이 값을 고정시켜 둬야 비교가 가능하다.)
Training
어떤 모델을 사용하느냐에 따라 학습되는 정보가 다르며, 데이터를 보고 정해준 기준에 따라 정보를 학습한다. 학습된 정보를 기준으로 판단(예측)하며, 판단한 내용으로 성능을 평가한다.

정리하자면, 주어진 데이터로부터 정보를 얻어서 성능이 향상될 수 있는 방향으로 점차 파라미터를 업데이트해 나가는 과정을 학습=training이라고 부른다.
Inference
inference란, 학습된 머신러닝 모델에 test 데이터를 넣어서 결과를 넣는 것 즉 최종 단계이다.
따라서, 추론단계에서는 더 이상 학습이 이뤄지지 않는다 즉 파라미터를 더 이상 업데이트하지 않는다.
Feature engineering
feature engineering이란 머신러닝 알고리즘이 잘 작동할 수 있도록 하는 feature들을 만드는 과정으로 그 과정에서 데이터에 대한 도메인 지식도 사용되기도 한다.
이 과정은 모델 성능에 매우 많은 영향을 끼치기 때문에 중요하면서도 어려운 작업이다

feature engineering이라는 큰 범주에는 다양한 방법들이 포함되는데, feature extraction / feature selection / feature construction 등이 있다.
Feature extraction
feature extraction은 원본 특징들의 조합으로 새로운 특징을 생성하거나, 고차원의 feature 공간을 저 차원의 새로운 feature 공간으로 투영하는 것을 말한다. PCA(Principal Component Analysis), AutoEncoder 등이 있는데 이 방법들은 나중에 따로 설명하도록 하겠다. 최근에는 딥러닝을 이용하여 새로운 feature을 생성하는 임베딩 방식을 사용하기도 한다.
Feature selection
feature selection 과정은 불필요한 특징을 제거하는 등 간결한 특징 집합을 만드는 과정이다. 이러한 과정에서 도메인 지식이 활용될 수 있다.

Feature construction
feature construction 과정은 가장 어려우면서 시간이 많이 걸리지만 성능에 큰 영향을 끼치는 방법이다.
주어진 데이터로부터 도메인지식등을 활용하여 새로운 특성을 만드는 것을 말하며 이 과정이 대표적인 feature engineering이라고 부른다.
feature engineering techinque
이러한 피쳐엔지니어링을 진행하는 대표적인 방법들이 몇 가지 있는데 간단하게만 알아보자.
1. Imputation - 데이터의 결측치를 채움
2. handling outliers: 데이터의 이상치를 처리
3. binning: 근처의 값들을 하나의 범주로 묶는 등 크게=robust 하게 학습 -> 오버피팅 방지
4. log transform: 한쪽으로 편향된 데이터를 분포가 정규분포에 가깝게 만들어주는 것 = 이상치의 영향을 줄이고 모델을 robust 하게 만듦
5. one-hot encoding: 범주형 변수를 학습에 이용하기 위해 숫자타입으로 변형
6. 그룹화: 분석을 보다 용이하게 할 수 있으며 변수들을 정리.
7. feature split: 다양한 방법이 존재->도메인 지식활용 혹은 수학적 지식 활용
8. scaling: 정규화나 표준화등 데이터의 범위를 통일시키는 과정
Loss Function(손실함수)
loss function, 손실함수는 지도학습 시 알고리즘이 예측한 예측값과 실제 정답의 차이를 비교하기 위한 함수 즉 학습 중 알고리즘이 얼마나 잘못 예측했는지를 나타내는 정도를 말한다.
손실함수는 이러한 잘못 예측하는 정도를 최소화하겠을 목적으로 최적화 Optimization을 진행하기 때문에 Objective Function이라고도 부른다.
손실함수와 평가지표를 혼동하면 안 되는데, 평가지표=성능지표는 알고리즘의 학습이 끝났을 때 모델의 성능을 평가하기 위한 지표로 (F1, 정밀도)등이 있으며 손실함수는 모델 학습 중에 학습이 얼마나 잘되고 있는지를 나타내는 지표이다.
차이 loss 이기 때문에 적을수록 학습을 잘한 것이며, 이러한 loss를 줄이기 위해서 파라미터=가중치를 업데이트하는 방식을 사용한다. 이 loss function의 결과가 가장 작아지도록 파라미터를 찾는 것이 주목적이다.


loss space에서 최적의 파라미터 조합을 찾는 것은 매우 어렵다.
현실적으로 최적의 파라미터 조합을 찾을 수 있는 gradient descent algorithm= 경사하강법이 제일 많이 사용된다.

경사하강법
더 자세한 설명은 아래 글을 참조하시면 됩니다!! 여기서는 간단하게만 정리하였습니다.
Gradient Descent: 경사하강법
딥러닝에서 손실 함수의 값이 최소가 되도록 모델의 파라미터를 조정하는 최적화 알고리즘에 대하여 정리해봤다. 우선 최적화알고리즘에 쓰이는 경사하강법을 알기 전에 미분에 대하여 먼저
changsroad.tistory.com
경사하강법은, 함수의 값이 낮아지는 방향으로 각 독립변수들의 값을 변형시키면서 함수가 최솟값을 갖도록 하는 독립변수의 값을 탐색 방법을 의미하며 일반적으로 입력된 Parameter의 검증(Validation)이 필요할 때 사용하는 방법이다.
보통 함수의 최솟값을 찾을 때는 미분계수가 0인지점을 찾는다. 그러나 단순 미분하여 0이 되는 지점을 찾는 것이 아니라, gradient descent를 이용하는 이유는 실제로 우리가 만나는 함수들은 닫힌 형태가 아니거나, 미분계수를 계산하기가 어렵기 때문이다.

gradient descent를 쉽게 말하면, 함수의 기울기를 이용하여 x의 값을 어느 쪽으로 옮겼을 때 함수가 최솟값을 갖는지 찾는 것이다. 기울기가 양수라는 것은 x가 증가할수록 y가 증가한다는 것이고, 기울기가 음수라는 것은 x가 증가할수록 y가 감소한다는 것이다. 또한 기울기의 절댓값이 크다는 것은 x가 최소, 최댓값과 멀리 떨어져 있다는 의미와도 같다.
이 개념을 이용해서 x가 커질수록 함숫값이 커지고 있다면, x를 줄여야 할 것이고, x가 커질수록 함수가 작아진다면 x를 x를 양의방향으로 옮겨야 한다.
요약: 기울기의 부호와 반대방향으로 움직여야 한다. 따라서 아래와 같은 최적화함수를 작성해 볼 수 있다.


gradient descent에도 단점이 존재하는데, 위와 같이 기울기가 감소하는 방향으로 x를 옮길 때 한 번에 얼마큼 움직이느냐를 step size라고 부르는데, 이 step size가 너무 클 경우 최솟값을 계산하지 못하고 계속 발산하고, 너무 작을 경우는 시간이 너무 오래 걸릴 것이기 때문에 적절한 step size를 선택해야 한다.
이러한 step size를 나타내는 파라미터를 learning rate라고 표시하고 0~1 사이의 값으로 조절할 수 있다.
이 learning rate를 사용자가 직접 정해야 한다는 것이 단점이다.

local minima
경사하강법의 문제는 local minima= 지역해에 있다. gradient descent 알고리즘을 시작하는 위치를 랜덤으로 정하는데 아래 그림에서처럼 어디를 random으로 정하느냐에 따라 올바르지 못한 값을 고를 수도 있다.

Evaluation Metric(평가지수)
머신러닝 모델의 성능을 평가하는 방법은 어떠한 task를 수행하는지에 따라 다르기 때문에 각 평가 지수마다 중요하게 보는 기준이 다르다. 회귀와 분류의 자세한 평가지표는 아래에 기록해 두었다.
Evaluation metric(분류 평가 지수)
모델 성능 평가란, 실제값과 모델에 의해 예측된 값의 차이를 구하는것. 실제값과 예측값이 오차가 0인 것은 실질적으로 힘들기 때문에 오차의 한계를 정해서 그 오차까지는 허용해준다. 성능평
changsroad.tistory.com
'ML & DL > 개념정리' 카테고리의 다른 글
| 분류와 회귀 (0) | 2023.12.11 |
|---|---|
| Evaluation metric (평가 지표) (1) | 2023.12.11 |
| 부스팅(Boosting) 알고리즘 (0) | 2023.11.30 |
| Clustering: 클러스터링 (0) | 2023.11.28 |
| 데이터사이언스 시작 (0) | 2023.11.24 |