
드디어 마지막 모델링 과정이다.
사실 모델링 부분은 코드는 열심히 짰지만 뭐 보여줄 것이 없긴 하다만, 열심히 작성해 보겠다.
1. 베이스라인 모델
우선 모델 자체는 딥러닝 모델이 아닌 머신러닝 모델을 사용하고자 했다. 이전에 제대로 된 튜닝 없이 LSTM을 돌려보기는 했었는데, 아무래도 이런 정형 데이터 특성상 트리 기반의 모델이 더 성능이 잘 나왔었다.
어떤 모델을 쓸지 고민을 하다가 그냥 젤 좋은 모델을 써야지 하는 생각에 AUTOML을 이용하여 모델을 선정하고자 했다.
1-1. input 데이터 확인
우선 automl 모델 선정 및 input 데이터를 만들기 전에 우선 데이터부터 다시 살펴보자.
이제 제일 중요한 부분이 나온다!!!!!!!!! 바로 target을 shift 해줘야 한다는 것이다.
우리는 현재 시점의 데이터들을 이용하여 현재 대교들의 수위를 예측하는 것이 아닌, 현재 데이터를 이용하여 10분 뒤의 수위를 예측하는 것이다. 10분 뒤의 수위를 예측하기 위해서는 당연히 현재 수위 또한 매우 중요한 column일 것이다.
따라서 우선 target 칼럼을 복사해 준다. 그럼 데이터 프레임이 아래와 같을 것이다.
| feature | prev_target | target | |
| 1/2 00:10 | a | AA | AA |
| 1/3 00:20 | b | BB | BB |
| 1/4 00:30 | c | CC | CC |
| 1/5 00:40 | d | DD | DD |
자 축소시켜서 살펴보면 우리는 a와 AA를 이용해서 BB를 예측해야 하고, b와 BB를 이용해서 CC를 예측해야 한다.
현재 데이터프레임이 위의 표처럼 되어있기 때문에 target을 제외한 feature들을 모두 shift(1) 해준다. 그럼 데이터프레임이 아래와 같이 변하게 된다.
| feature | prev_target | target | |
| 1/2 00:10 | nan | nan | AA |
| 1/3 00:20 | a | AA | BB |
| 1/4 00:30 | b | BB | CC |
| 1/5 00:40 | c | CC | D |
이제 맨 첫 번째 줄은 nan이기 때문에 데이터프레임을 1행부터로 바꿔준다.
TARGET_BRIDGE = 'wl_jamsu'
data["prev_"+TARGET_BRIDGE]=data[TARGET_BRIDGE].copy()
X_train = data.drop(columns=[TARGET_BRIDGE]).shift(1)
X_train = X_train.iloc[1:]
y_train = data[TARGET_BRIDGE].iloc[1:]
train=pd.concat([X_train,y_train],axis=1)
이렇게 데이터 프레임을 만져주면, 10분 뒤의 수위를 예측하는 문제로 설정할 수 있다.
이 과정을 빼먹거나 잘못 shift 하면 정답 수위를 가지고 정답 수위를 예측하거나, 미래수위를 가지고 과거 수위를 예측하거나, 현재 값들로 현재 수위를 예측하는 등 다양한 data leakage 및 위반사항에 해당하게 된다.
1-2. automl
AUTOML도 여러 가지를 써봤었는데, 예전에 써봤던데 lazypredict 그리고 이번에 최종적으로 사용한 것이 pycaret이다.
둘 다 automl로 간단한 코드 몇 줄로 여러 모델을 시험해 볼 수 있으며 두 라이브러리 모두 다양한 기능을 참고하니 취향에 맞게 사용해 보면 좋을 것 같다. (pycaret이 좀 더 최신이고 정리도 잘 돼있는 것 같긴 하다. 단 기능적인 면에서는 lazypredict도 좋다.)
GitHub - shankarpandala/lazypredict: Lazy Predict help build a lot of basic models without much code and helps understand which
Lazy Predict help build a lot of basic models without much code and helps understand which models works better without any parameter tuning - GitHub - shankarpandala/lazypredict: Lazy Predict help ...
github.com
PyCaret 3.0 - Docs
Compared with the other open-source machine learning libraries, PyCaret is an alternate low-code library that can be used to replace hundreds of lines of code with a few lines only. This makes experiments exponentially fast and efficient. PyCaret is essent
pycaret.gitbook.io
우선 pycaret의 특성상, 우리가 흔히 머신러닝 모델을 이용할 때 사용하는 scikit-learn의 api 방식과는 다르기 때문에 x와 y를 구분해서 넣지 않고 데이터를 합쳐서 넣은 다음, target 칼럼을 지정해줘야 한다.
그러게 pycaret 모델을 세팅한다.
# 모델을 선정하기위해 automl pycaret을 이용하여 선정. -> 한대교만을 기준으로 선정하였음.
test = setup(data=train, target='wl_jamsu', fold_strategy = 'kfold',fold=5, data_split_shuffle=True, use_gpu=True, verbose=False)
res = compare_models(include = ['lightgbm','xgboost','catboost','rf'], sort='rmse')
res
나는 우선 트리기반의 모델들만 비교하기 위해 모델을 직접 선정하여 적어줬고, 기준은 rmse로 선정하였으며 kfold방식으로 학습하도록 했다. 이렇게 비교한 결과 LightGBM 모델이 가장 성능이 좋게 나왔으며, 학습속도도 매우 빨랐기에 LightGBM 모델을 베이스라인 모델로 삼았다.
여기서는 모델을 선정하기 위해서만 사용하였고 나중에 기본 LGBM을 이용하여 실제 데이터 기간에 맞게 실험을 진행하였다.
2. 모델 종류
우선 코드를 본 사람은 이해해 주겠지만, 정말 코드 짜는 것에 신경을 많이 썼다.. 이렇게까지 할 필요 있었나 싶다가도 코드 정리하는 것이 재밌어져 버렸다.. 이 시간에 딴 거 공부할 것이 산더민데..
아무튼 다양한 함수들을 정의하여서 각 대교의 이름을 넣으면 모델 훈련 및 튜닝까지 진행되도록 만들었는데, 이 얘기는 나중에 하도록 하고, 우선 모델부터 설명해 보자.
나는 총 3가지 모델 형태를 만들었다.
1) 각 월의 데이터로 학습하여 각 월을 예측 EX) 2013년~2022년 1월의 데이터들만 학습하여 2023년 1월 예측
수위가 이전에 EDA에서 확인했듯이 각 월마다 일정한 패턴들을 보인다는 것을 확인하였고 수위의 차이의 최대 폭은 대략 800 정도가 되었기에 같이 학습하면 무리가 있을 것 같았다. 그래서 월별로 학습 및 예측을 진행하였다.
2) 홍수기와 갈수기로 나누어 학습 및 예측
이것 또한 위와 같은 이유이지만, 홍수기에 초점을 맞춰서 6월~9월로만 학습시키고 6~9월 예측, 나머지로 학습 및 예측을 진행하였다.
3) 전체로 학습 및 예측
가장 기본적인 방법으로 어차피 월이랑 시간은 COLUMN에 포함되어 있으니 그냥 전체 데이터를 이용한 학습
3. 모델 학습 및 튜닝
이제 위와 같이 모델을 나누기로 결정했기 때문에 각 대교별로 학습 및 추론을 진행하였다.
이것도 Multi output regressor이라고 해서 한 번에 4개 대교의 수위를 예측하는 것도 있지만, 각각 하는 것이 더 좋다고 생각하여 각 대교별로 학습 및 튜닝을 진행하였다.
사실 모델 학습 및 튜닝 부분의 코딩이 가장 자랑하고 싶은 부분인데... 정말 사용하는 사람이 선행시간과 대교 모델옵션만 클릭하면 알아서 돌아가도록 만들고.... 정말 힘들었는데... 코드 자랑? 은 누구도 궁금해하지 않으니 나만 뿌듯.... 깃허브 star 눌러주세요.. 제발
우선 gpu를 사용하여 학습하였으며, 기존 optuna에는 early stopping option이 없기에 stack over flow에서 얻은 코드를 사용하여 early stopping을 적용하였다. 또한 sklearn-intelex도 사용하였다.
(gpu세팅이나, sklearn-intelex는 제 블로그 참조하시면 자세하게 설명되어 있습니다.)
방식은 다음과 같은 파이프라인을 따른다.
0) 예측하고자 하는 대교와 선행시간(이 프로젝트에서는 10분 고정) 선택
1) 모델 옵션 선택 -> 위에서 설명한 3가지 방식 (1/2/3으로 선택)
2) 선택한 모델 방식, 선행시간에 맞는 데이터 형식이 생성됨.
3) optuna+kfold(5)를 이용한 파라미터 튜닝 ->gpu 사용
4) 모델 결과 병합
위 파이프라인을 주저리 설명하자면 우선 대교별로 학습할 것이기 때문에 대교와 선행시간 여기선 10분을 정해준다.
그리고 모델옵션 어떤 기준으로 학습하고 추론할 것인지를 정해주면 예를 들어 1번을 선택하면 각월별로 학습을 진행하는 함수를 실행시키고, 2번이면 홍수기 갈수기로 데이터를 나누고 3번이면 전체가 들어간다.
이후 1번을 선택했다면 각월별 총 12개의 모델이 optuna를 이용하여 파라미터를 튜닝하며 학습된다.
2번을 선택했다면 2개의 모델, 3번이라면 1개의 모델 그러니까 총 15개의 모델이다.
게다가 나는 100 epoch를 설정(early stopping=15)하였기 때문에 학습에 매우 오랜 시간이 걸렸다.(전체 대략 60개의 모델이므로 3~4일 정도가 풀로 걸렸다)
아무튼 묻고 따지지 말고 최종결과를 보자. 사실 모든 데이터의 결과를 블로그에 첨부하기는 어렵기 때문에 github image폴더에 업로드할 것이다.
4. 결과 비교
최종적으로 나는 모든 대교를 3가지 방법으로 전부 학습하여 결과를 비교했다.
# 3개의 모델(전체월, 비홍수기, 홍수기)을 이용하여 test 셋의 rmse를 가장 잘 예측한 모델을 확인.
def finalize_modeling(leadtime,bridge):
overall_rmse_list = []
print("#" * 50)
print(f"{bridge} Predict report for Leadtime {leadtime}:\n")
# 변수명들을 동적으로 불러올 수 있도록 globals()사용
results = [globals()[f"{bridge}_lt{leadtime}_monthly"], globals()[f"{bridge}_lt{leadtime}_flood"], globals()[f"{bridge}_lt{leadtime}_total"]]
rmse_best = pd.DataFrame(index=range(1, 10), columns=['Model 1', 'Model 2', 'Model 3', 'Best Model'])
for month in range(1, 10):
best_rmse, best_model_name = float('inf'), None
for i, model in enumerate(results):
model.index = pd.to_datetime(model.index)
model_month = model[model.index.month == month]
answer_month = answer[answer.index.month == month]['wl_'+bridge]
if not model_month.empty and not answer_month.empty:
rmse = mean_squared_error(answer_month, model_month,squared=False)
rmse_best.loc[month, f'Model {i+1}'] = rmse
if rmse < best_rmse:
best_rmse, best_model_name = rmse, f'Model {i+1}'
rmse_best.loc[month, 'Best Model'] = best_model_name
print(rmse_best)
best_model_rmse = [rmse_best.loc[month, best_model] for month, best_model in enumerate(rmse_best['Best Model'], start=1)]
overall_rmse = np.sqrt(np.mean(np.square(best_model_rmse)))
overall_rmse_list.append(overall_rmse)
return overall_rmse각 대교별 상세 결과는 plot으로 github에 올려뒀으니 참고하면 될 것 같고,
최종 각 대교별 각 3개의 모델을 비교해 봤다. 평가지표는 대회의 평가지표를 이용하였다.
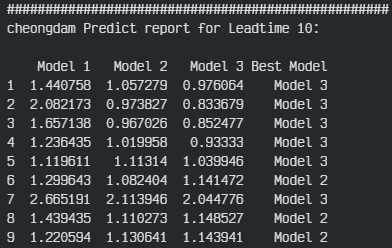
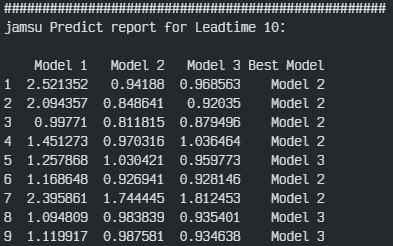
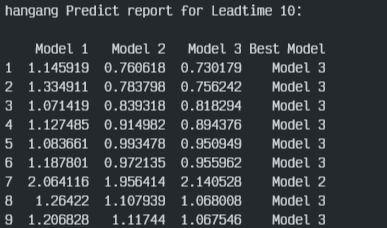
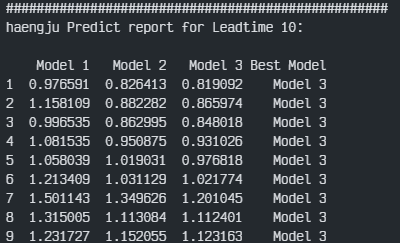
최종 결과부터 보자면 우선 Model 1, 즉 각 월별로 학습 및 예측을 진행하였던 결과는 성능이 매우 안 좋게 나왔다. 그리고 대부분이 전체데이터로 학습한 Model 3번이 가장 좋은 성능을 보였으며 잠수교에서는 홍수기와 갈수기를 나눠 학습한 Model 2가 가장 좋은 결과를 도출하였다.
--> 어느 부분에서 오차가 컸는지 등을 확인하고 싶으면 github의 image 폴더 내에 정리해 둔 각 대교별 각 모델별 결과를 확인하면 된다. 위는 단순히 정리하기 위한 것이다.
5. 결론
2013.01.01~2022.12.31의 데이터를 이용하여 2023.01.01~2023.09.31까지의 한강, 청담, 행주, 잠수교의 10분 뒤 수위를 예측하는 프로젝트를 진행하였으며, 각기 다른 세 가지(월별, 홍수기별, 전체)의 모델 훈련 방식을 선택하여 각 대교별로 학습 및 2023년 예측을 진행하여 결과를 확인하였다.
이에 잠수교를 제외한 나머지 3개의 대교는 전체를 이용한 학습 결과가 가장 좋았으며, 잠수교는 홍수기/갈수기를 나누어 학습한 결과가 가장 좋았음을 확인하였다.
이에 이어서 진행할 "선행시간에 따른 잠수교 수위 예측"에서 이러한 결과를 기반으로 모델링을 진행할 예정이다.
6. 프로젝트 회고
우선 데이콘과는 다른 test 기간을 지정하였으며, 내가 데이터 수집부터 전처리 모델링 결론까지 낸 제대로 된 프로젝트였다. 연구실에서 시작해서 결국 완성하지 못한 논문을 준비하며 시작했던 프로젝트의 시초인 이 대회를 드디어 완성했다.
사실 eda와 feature engineering이 나도 생각해 보고 다른 사람들 것도 많이 참조하였지만, 그다지 성능에 영향을 못 미친것 같기도 하고 할게 별로 없었던 것 같다. (결측치 채우는 것만 성능에 영향을 조금 끼쳤던 것 같기도,,)
이 블로그에는 어찌 됐던 결론, 최종결과만 작성한 것 이기에 별거 없어 보이지만 많은 시간을 썼고 많이 갈아엎었다.
진짜 전처리, 모델링만 거짓말 1도 안치고 10번은 전부 전부 전부 갈아엎었었다.
이후 뼈대가 정해지고 코드를 최대한 손쉽게, 첫 프로젝트인 만큼 깔끔하게 정리하고자 했다.
내 바람은 누군가가 이 코드를 이용하여 수정하고, 예측해 보고, 리뷰를 줬으면 좋겠다. 악플이던 뭐던 관심을.........
이 오랜 시간 사용한 코드를 아무도 안 읽을 것을, 아무도 돌려보지 않을 것을 알기에 너무 슬프디... 하하가
암튼!!!!!!!!! 이제 이 프로젝트는 끝이 났고, 이후에 이 카테고리에 이어서 개인 프로젝트를 이어서 작성할 것이다.
모두 내용은 똑같은데 조금 보완할 점만 보완해서 잠수교의 선행시간에 따른 분석만 진행할 것이다.(원래 쓰려던 논문 주제임 하,,)
보완할 점은 무엇이냐!!!!!!!!!
-> 우선 optuna의 파라미터.
나는 3가지 다른 모델 방식을 선택하였고 모델 방식마다 input 데이터의 크기가 엄청나게 다르다. 왜냐면 model 1번은 월별로 학습하고 2번은 7개의 달을 한 번에 학습하고 3번은 12개를 전부 학습하는데 optuna 파라미터 튜닝 범위를 전부 같게 줬다. 사실 이것 때문에 이 파라미터들이 전체 데이터크기와 어울려서 model 3번이 선택된 것일 수도 있지만 잠수교는 model 2번이 압도적으로 나왔기에... 개인 프로젝트 때 이 부분을 조심하여 튜닝할 것 같다.
-> 추가적인 feature engineering 혹은 전처리 혹은 모델
앞서 말했듯 이 프로젝트에서 내가 특별히 한 것이라곤 모델링 부분밖에 없는 것 같아 아쉬웠다.
이에 다른 전처리(isolation forest) 혹은 딥러닝 모델을 사용하여 잠수교 한 개 만을 예측하는 것으로 이어서 나가보려 한다.
사실 이 글은 누군가 읽어줄까?..ㅋㅋㅋㅋㅋ 코드 읽기랑 돌리기를 걱정할 게 아니라 이 글을 읽어줄 것 먼저 기대해야 하는데 하하하ㅏ하하하하하하하하 진짜 내 첫 프로젝트이자 젤 쓸데없이 시간도 많이 썼고 애정이 담긴 프로젝트 안녕 ㅋㅋ
ㄲ끝.. 제발 전 세계에 있는 단 한 명만이라도 깃허브 star을..ㅋ
끝.
GitHub - Bae-ChangHyun/Waterlevel-predict
Contribute to Bae-ChangHyun/Waterlevel-predict development by creating an account on GitHub.
github.com
'프로젝트 > 수위 예측' 카테고리의 다른 글
| 선행시간에 따른 잠수교 수위 예측 (0) | 2024.01.10 |
|---|---|
| 한강 수위 예측 - 데이터 EDA, 전처리, Feature engineering (1) | 2023.12.14 |
| 한강 수위 예측 - 프로젝트 소개 및 데이터 수집 (1) | 2023.12.14 |
| 한강 수위 예측 - 프로젝트 시작 (0) | 2023.12.13 |