

0.PyTorch Lightening
PyTorch Lighting은 구현하는 코드의 양이 늘어나면서 코드의 복잡성이 증가하고, 다양한 얽혀있는 요소들로 인해 복잡해지는 것들을 조금 더 간단하게 구현하도록 등장하였다. 이는 PyTorch를 좀 더 단순하고 이해하기 쉽게 만들어주는 오픈소스 라이브러리이며, 코드를 간단하게 작성할 수 있도록 돕는다.
PyTorch Lightening의 주요 기능들을 확인해 보자.
1. PyTorch Lightening 특징
1-1. 코드 추상화 & 하드웨어 호출
기존의 PyTorch는 `model`. `optimizer`,`training loop`를 전부 따로따로 구현해야 했다. 그러나 PyTorch Lightning에서는 `LightningModule`이라는 클래스 안에서 모든 것을 한 번에 구현할 수 있다. 추가적으로 기존의 PyTorch에서는 GPU를 사용하려면, `. to(device)`와 같은 형식으로 하드웨어를 넘겨줬어야 하는데, Lightning에서는 사용가능한 GPU가 있다면 우선적으로 사용된다.
1-2. Callback 함수, logging
PyTorch Lightning에는 다양한 내장 콜백함수를 지원한다. 예를 들어 초기 learnig rate를 찾아주거나, early stopping을 제공하는 콜백함수들을 한 줄의 코드로 쉽게 적용할 수 있다. 또한 TensorBoard나 WandB 등의 모니터링 툴을 쉽게 사용가능하도록 구현되어 있다.
1-3. 16-bit precision
최근 딥러닝 연구에서는 모델의 크기가 매우 크다. 이런 경우 모델 전체를 GPU에로드 하여 학습하는데 제한이 되는데. 일반적으로 딥러닝 모델에서 실수를 표현하는 비트 수가 32 bit인데 이를 줄여 모델의 계산 속도 향상과 메모리 사용량을 줄이고자 한 아이디어가 16-bit precision이다. 이 기능을 Lightning에서는 간단한 옵션으로 사용해 볼 수 있다.
2. LightningModule
PyTorch Lightning을 사용하기 위해서는 `LightningModule` 클래스를 상속받아 모델의 구조, 손실함수, 학습 및 평가방법, 최적화 알고리즘을 선언한다. 각각의 메서드에 대하여 간략하게 알아보자.
`__init__`:초기화를 담당하는 메서드로 모델의 레이어를 초기화한다. 또한 학습 및 평가 과정에서 사용되는 손실함스 및 메트릭을 선언한다.
`forward`: 모델을 통해 데이터가 연산되는 과정을 정의한다.
`configure-optimizers`: 최적화 알고리즘과 학습률 스케쥴러를 정의하고 반환한다. 반환 시 optimizer, scheuduler 순서로 반환해야 하며 스케쥴러는 생략가능하다.
`traing_step`:학습 데이터셋의 미니 배치에 대한 손실을 반환하는 과정을 정의한다. 모델 학습과 관련된 `optimizer.zero_grad()`나 `loss_backward`,`optimizer.step()`등을 작성하지 않아도 된다.
`validation_step`: validation set의 미니 배치에 대한 모델의 성능을 확인하는 과정을 정의
`test_step`: test set의 미니 배치에 대한 모델의 성능을 확인하는 과정을 정의
`predict_step`:추론해야 하는 데이터셋의 미니 배치에 대한 예측 과정을 정의
import torch
import torch.nn as nn
from torch.optim import Adam
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
import pytorch_lightning as pl
class LitMNIST(pl.LightningModule):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1)
self.fc1 = nn.Linear(64*5*5, 128)
self.fc2 = nn.Linear(128, 10)
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, x):
x = torch.relu(self.conv1(x))
x = torch.relu(self.conv2(x))
x = x.view(x.size(0), -1)
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
def training_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = self.loss_fn(logits, y)
self.log('train_loss', loss)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = self.loss_fn(logits, y)
self.log('val_loss', loss)
def configure_optimizers(self):
return Adam(self.parameters(), lr=0.001)
train_dataset = MNIST(root='data/', train=True, transform=ToTensor(), download=True)
train_dataloader = DataLoader(train_dataset, batch_size=64, num_workers=4)
val_dataset = MNIST(root='data/', train=False, transform=ToTensor(), download=True)
val_dataloader = DataLoader(val_dataset, batch_size=64, num_workers=4)
model = LitMNIST()
trainer = pl.Trainer(gpus=1, max_epochs=10, progress_bar_refresh_rate=20)
trainer.fit(model, train_dataloader, val_dataloader)3. Trainer
Trainer은 위에서 정의한 LightningModule의 메서드를 이용하여 모델학습을 실행한다. 여기서 콜백함수를 사용하거나 로깅도구를 설정하여 관리할 수도 있다.
`.fit()` 메서드를 이용하여 모델과 train_dataloader, val_dataloader을 인자로 받아 학습을 진행된다.
이때 받아온 모델, 즉 LightningModule로 정의한 모델의 training_step, validation_step, configure_optimizers가 차례로 호출되어 학습이 진행된다.
`.validate()`: 모델과 val_dataloader을 인자로 받아 validation set에 대한 평가를 진행한다. LightningModule에 있는 validation_step 메서드를 호출하면서 메트릭을 출력한다.
`test()`: 모델과 test_dataloader을 인자로 받아 test set에 대한 평가를 진행한다. 이는 LightningModule에 있는 test_step 메서드를 호출하면서 메트릭을 출력한다.
`predict()`: 모델과 추론하고자 하는 dataloader을 인자로 받아 모델의 결괏값을 반환한다. LightningModule에 있는 predict_step 메서드를 호출하면서 메트릭을 출력한다.
model=Classifier(num_classes=10,dropout_ratio=0.2)
trainer=Trainer(
max_epochs=100
accelerator='auto'
callbacks=[callbacks.EarlyStopping(monitor='valid_loss',mode='min')],
logger=CSVLogger(save_dir='./csv_logger',name='test'))
trainer.fit(model,train_dataloader,valid_dataloader)
이러한 Trainer을 사용하면 분산 학습 환경과 같이 복잡한 환경에서도 학습 환경을 관리해 줄 수 있다. 기존에는 하나의 PC에서 여러 개의 gpu를 사용하거나, GPU가 있는 PC를 여러 개 사용하여 학습하는 코드를 작성하는 것은 매우 복잡하였다.
이는 학습 루프를 자동으로 관리하여 데이터 로더와 관련되 반복문을 따로 명시하지 않아도 된다.
아래의 사진만 보더라도 PyTorch Lightning의 장점을 확연하게 볼 수 있다.

4. 실습
여기서부터는 PyTorch와 PyTorch Lightning을 비교해 보면서 어떻게 다른지를 확인해 보겠다.
4-1. __init__


`__init__`에서 다른점은 우선 상속받는 모듈이 PyTorch에서는 `nn.Module`이고, Lightning에서는 `LightningModule`이라는 점과, Pytorch에서는 optimizer이나 evaluate 등을 따로 구현하기 때문에 init에 포함하지 않지만 Lightning의 경우에는 learning rate, accuracy, loss를 따로 정의해준 것을 볼 수 있다.
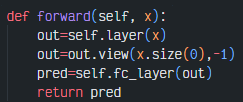
4-2. forward
다음으로 forward 메서드는 동일하게 작성하면된다.
4-3. configure_optimizers
PyTorch에서는 외부에서 최적화 알고리즘과 스케쥴러를 설정해 줬는데, Lightning에서는 같은 클래스 안에 정의한다.


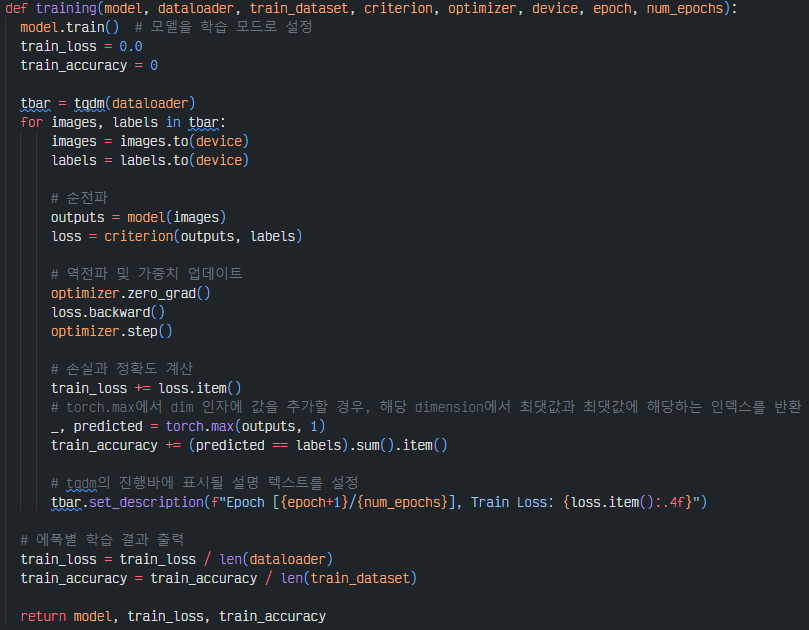
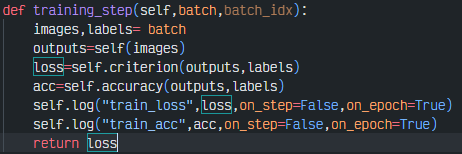
4-4. training_step
trainin_step 메서드는 미니 배치를 받아 학습 연산과정을 거쳐 손실을 반환하는 코드를 작성하는데 Lightning에서는 기존 PyTorch와는 다르게 `to.device()`, `model.train()`,`optimizer.zero_grad()`,`loss_backward`,`optimizer.step()`을 생략해도 된다.
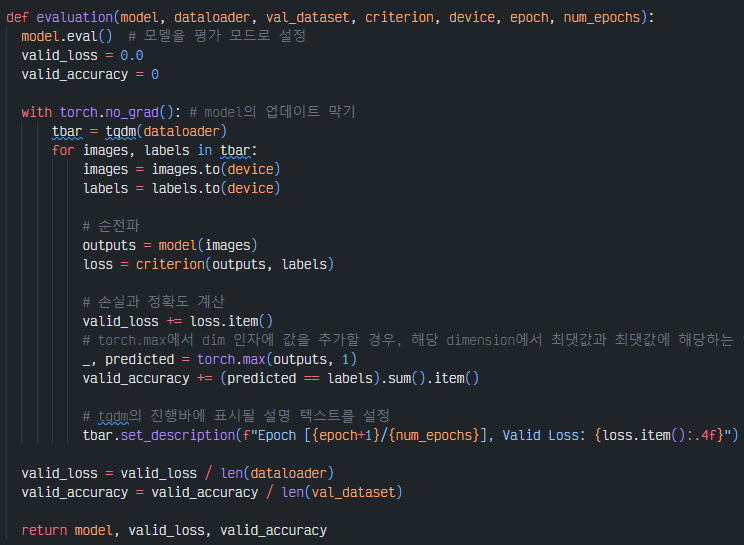
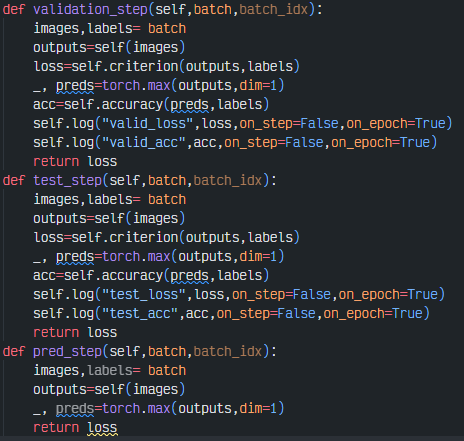
4-5. validation_step, test_step,pred_step
위와 마찬가지로 미니 배치를 받아 추론 과정을 거친 후 로그를 기록하는 코드
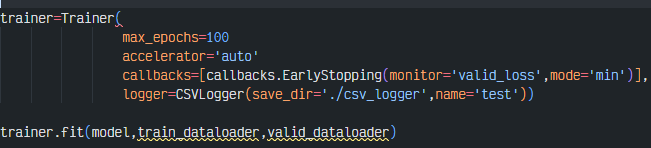
4-6. Trainer
아래와 같이 callback함수들과 모니터링을 위한 logger을 사용가능하다.
'ML & DL > 개념정리' 카테고리의 다른 글
| 연속형, 범주형 변수 처리 (0) | 2024.01.11 |
|---|---|
| 데이터 전처리(이상치&결측치) (0) | 2024.01.10 |
| Hugging Face를 이용한 Finetuning 실습 (0) | 2024.01.09 |
| Timm을 이용한 Finetuning 실습 (0) | 2024.01.09 |
| Pretrained Model (0) | 2024.01.09 |