

0. VGGNet
VGGNet은 앞서 올린 AlexNet보다 2년 뒤에 나온 모델로 layer의 개수가 많이 증가하고 성능 또한 매우 향상된 것을 볼 수 있다.
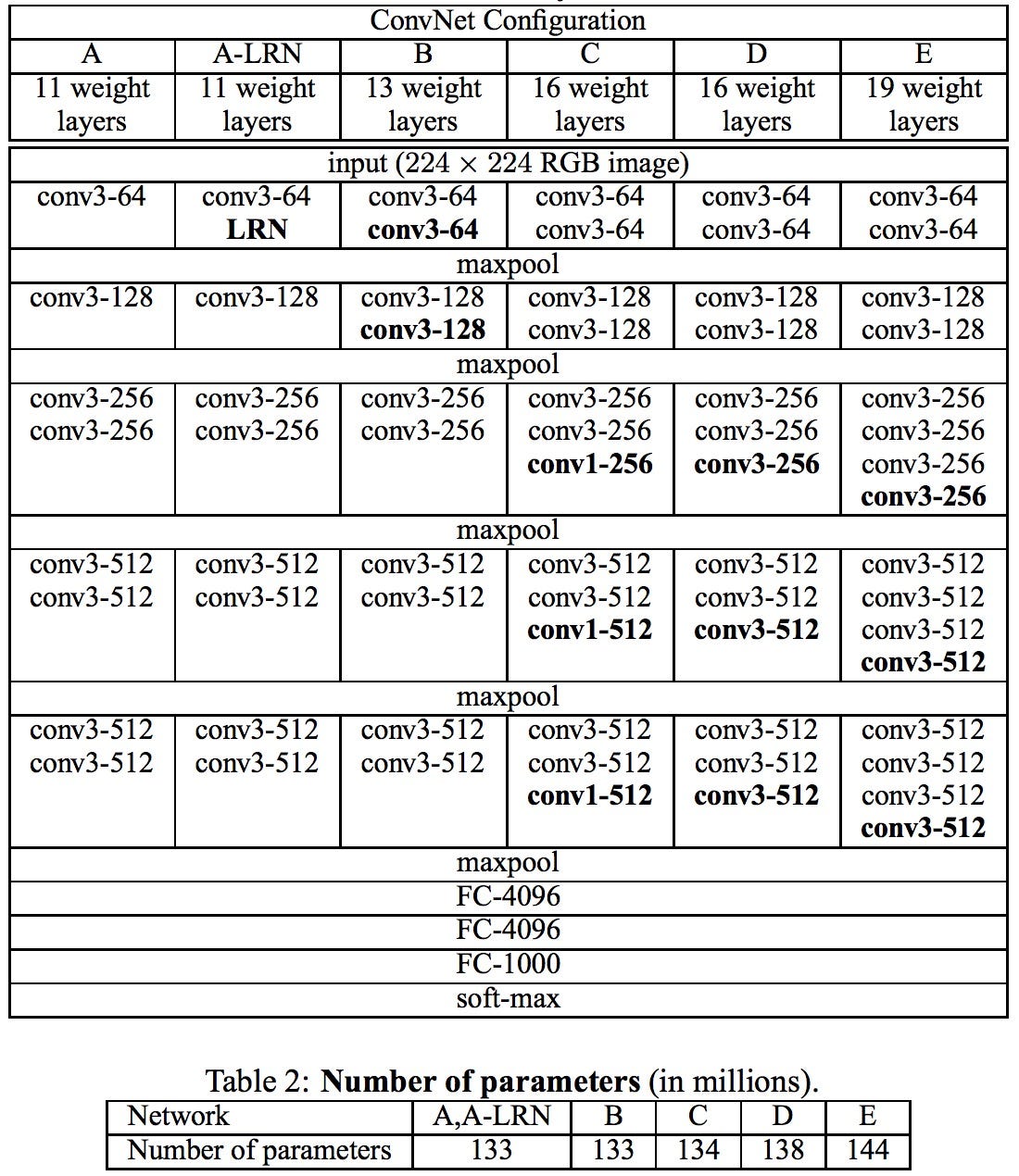
VGGNet은 네트워크의 깊이가 깊어질수록 성능의 변화에 대한 것을 분석해 보자고 하였다. 따라서 컨볼루션 필터 사이즈를 가장 작은 3x3으로 고정을 하고 레이어의 깊이를 깊게 만들어 비교하였다.
아래가 해당 연구에서 실행해본 구조들이며 현재에는 일반적으로 16개의 layer을 쌓은 것과 19의 layer을 이용한 VGGNet을 사용한다.

1. 커널 사이즈
우선 앞서 말했듯이 VGGNet은 컨볼루션 레이어의 필터 크기를 모두 3x3으로 고정하였는데 이것에 대하여 알아보자.
기존의 AlexNet 같은 경우에는 초반에 size=11, size=5 등의 큰 필터등을 사용했었는데, 그렇기 때문에 파라미터의 수도 매우 많이 증가하였다.
아래의 그림을 보면 3x3의 필터를 여러 번 적용하면 5x5나 7x7과 동일한 사이즈의 feature map을 산출할 수 있으며 더 적은 파라미터를 사용하게 된다는 장점이 있다.
좌측이 7x7필터를 적용했을 때고, 우측이 3x3필터를 3번 적용하여 산출한 featuremap인데, 동일한 수용능력을 보임을 알 수 있다. 이때 7x7필터를 한번 적용했을 때는 파라미터 수가 49이고, 3x3필터를 적용했을 때는 총 27개이다. 추가로 각 컨볼루션 레이어를 거치며 비선형함수 relu도 여러 번 거치게 된다는 특징이 있다.
즉, 큰 크기의 필터대신 작은 크기의 필터를 사용함으로써 더 적은 파라미터를 사용하고 relu함수를 더 거치게 된다.



이 외에도 학습과 평가방법에서 overfitting을 방지하기 위하여 `Scale jittering`이라는 기법을 이용하여 data augmentation을 하였는데, 이것은 추후에 다뤄보도록 하겠다.(아래 블로그에 해당 내용이 자세하게 적혀있어 가져와봤다.)
7. VGGNet
안녕하세요~ 이번시간에는 VGGNet이라는 CNN모델에 대해서 설명드릴거에요~ 이전에 설명드린 AlexNet의 등장으로 image classification 분야에서 CNN 모델이 주목을 받기 시작했어요. 그리고 이후 연구자들
89douner.tistory.com
[CNN Network] 3. VGGNet
아래 내용은 CNN Network를 공부하며 onlybox.log 를 참고하여 작성된 내용입니다. 연관게시글 더보기 1. LeNet-5 2. AlexNet 3. VGGNet 4. GoogLeNet VGGNet? VGGNet은 OxFord대학교의 Visual Geometry Group이 개발한 CNN Network
eunhye-zz.tistory.com
이 VGGNet모델은 ImageNet대회에서 GoogleNet에 밀려 2위를 했지만, 네트워크가 깊어지면서 성능향상이 된 것을 실험하여 추후에 아주 깊어지는 모델들에게 영향을 줬다.
'ML & DL > Computer vision' 카테고리의 다른 글
| Semantic segmentation 방식 (0) | 2024.02.02 |
|---|---|
| EfficientNet (0) | 2024.01.30 |
| AlexNet (0) | 2024.01.30 |
| Backbone과 Decoder 개념 (0) | 2024.01.29 |
| Contour Detection (0) | 2024.01.29 |