이번에는 여러 Image segmentation 중 semantic segmentation에 대하여 조금 더 자세하게 알아볼 것이다.

1. Sliding Window

이미지를 sliding window로 옮겨가면서 각 window를 CNN에 넣어 해당 window의 중심에 그 class를 할당하자!
(원래는 각 픽셀별로 하는 것이 맞지만 각 픽셀은 너무 작아 특징을 포함할 수 없기 때문에 주변을 같이 인식하고 클래스만 각 픽셀에 부여)
-> 매 픽셀마다 클래스를 예측할 때 sliding window의 크기만큼의 작은 정보만을 줄 수 있기 때문에 해당 window 밖의 정보를 반영할 수 없음
-> 매 픽셀마다 window 크기를 보는데, 모든 픽셀에 대하여 수행하므로 중복 연산 과정을 수행한다.
2. Size Preserving Convolutional Layers

기존 CNN처럼 이미지 하나를 넣는 방식이지만 Convolution 연산을 할 때 원래 이미지의 사이즈를 잃지 않고 보존하게 하자!
-> 기존 cnn연산과 동일한 연산량
-> 기존 크기를 유지하려면 padding을 많이 사용해야 하고 이는 실제 이미지와 무관한 값. == Receptive field가 제한
3. Downsampling + Upsampling
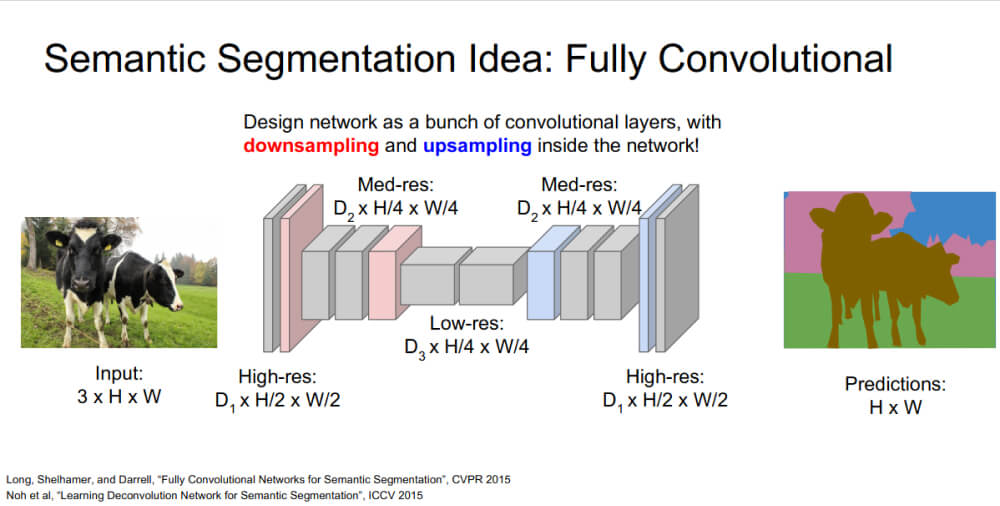
마지막 방법은 기존의 cnn 방식처럼 Downsampling하면서 feature을 뽑고 다시 Upsampling을 하여 원래의 크기로 바뀌는 방법이다.
-> 큰 Receptive Feild를 가짐.
'ML & DL > Computer vision' 카테고리의 다른 글
| Computer vision Metric (0) | 2024.02.23 |
|---|---|
| FCN: Fully Convolutional Network (0) | 2024.02.02 |
| EfficientNet (0) | 2024.01.30 |
| VGGNet (0) | 2024.01.30 |
| AlexNet (0) | 2024.01.30 |