

1. Grad-CAM 소개
CAM은 Global average pooling layer가 없는 모델들에 한해서는 사용하기 어려웠고(사용하려면 모델 재학습 필요), 마지막 feature map에 대한 것만 시각화할 수 있다는 단점이 존재하였다.
이때 기존 네트워크 구조를 그대로 유지하면서 CAM과 유사하게 특징맵을 시각화할 수 있는 Grad-CAM이 2017년도에 등장하였다.
2. Grad-CAM 원리
우선 간단하게 CAM과의 차이를 말하자면, CAM은 Global Average Pooling layer을 거쳐 나온 벡터를 fc layer에 통과시킴에 따라 가중치를 계산하여 해당 가중치를 feature map에 곱하는 방식이었고, Grad-CAM은 동일한 원리인데 가중치를 GAP을 거치는 것이 아닌 Gradient를 이용하여 얻는다. 따라서 따로 네트워크 구조를 변경하지 않고 사용가능하다.
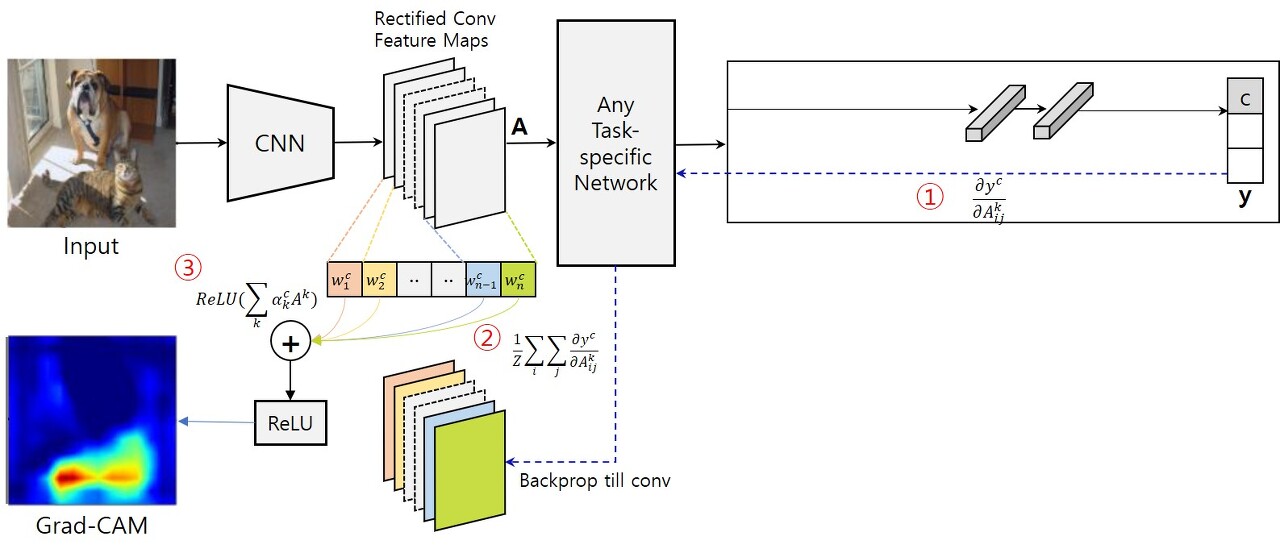
어떠한 네트워크라도 특정 featuremap이 추출된후 특정 연산을 거쳐 확률이 나오게 된다.

위의 그림에서 softmax를 취하기전의 결괏값을 $y^{c}$라고 할 때 마지막 convolution layer의 feature map $A^{k}$에 대한 영향을 구하려고 하면 해당 그래디언트 값을 구하면 된다. 즉 $ \frac{\partial{y^{c}}}{\partial{A^{k}}} $ 를 구해볼 수 있다.
이 그래디언트를 feature map $A^{k}$의 모든 원소에 대하여 계산하고 Gloabl Average Pooling을 적용하면 각 feature map 당 한개의 값을 얻을 수 있는데 이것을 $\alpha^{c}_{k}$ 라고 하며 해당 값은 출력값 y에 대한 역전파 과정을 수행한 것이기 때문에 중요도라고 볼 수 있다.
(Grad CAM은 CAM의 일반화 버전?? )
사실 CAM에서는 각 feature map을 Gloabal average pooling한 값을 fc layer을 거치며 학습하여 가중치를 얻기 때문에 해당 가중치가 그 feature map에 대한 중요도라는 직관적인 느낌이 있는데, 위에서 구한 gradient는 구할 순 있는데 그 gradient가 왜 중요도를 나타내는지 모를 수도 있다.
해당 결과는 네트워크 구조에 CAM에서와 동일한 Global average pooling layer이 있다고 가정하고 식을 풀어봤을 때 CAM과 Grad-CAM의 가중치 식이 동일하게 나왔다.
아래 블로그에 해당 내용에 대한 수식적인 내용이 자세하게 나와있다.
[6주차] 논문리뷰: CAM, Grad-CAM, Grad-CAM++
본문에서는 시각화 기법인 CAM, Grad-CAM, Grad-CAM++에 대해 알아보았다.
velog.io
이제 CAM에서와 동일한 방식을 적용하면 되는데 각 feature map마다 얻어진 $\alpha^{c}_{k}$에 해당 feature map을 곱하여 값을 얻게 되고, 또 추가된 것은 해당 결과에 ReLU함수를 거쳐 positive 한 결과만을 얻을 수 있게 해 줬다.(ReLU는 양의값만 그대로 출력하므로)
아래의 그림에 위에서 설명한 내용을 요약하고 있다.


3. Grad-CAM 장점
Grad-CAM은 Global average pooling이 적용되지 않은 어떠한 네트워크 구조에도 적용할 수 있게 되었고, 추가로 모델 구조에 변형을 가하지 않기 때문에 성능의 손실 또한 없앴다.

'ML & DL > 개념정리' 카테고리의 다른 글
| PCA-주성분 분석 (0) | 2024.02.27 |
|---|---|
| CAM: Class Activation Map (0) | 2024.01.31 |
| Activation Function: 활성화 함수 (0) | 2024.01.31 |
| Feature engineering (0) | 2024.01.11 |
| 연속형, 범주형 변수 처리 (0) | 2024.01.11 |