
0. Computer vision task
Computer vision task에는 아래와 같이 다양한 task들이 있다.
Classification: 한 이미지가 있을 때, 그 이미지의 클래스를 분류
Object detection: 한 이미지에서 각 객체의 클래스가 무엇이고, 그 객체의 박스형 위치 탐지
Segmentation: 한 이미지에서 각 객체의 클래스가 무엇인지, 그 객체의 픽셀 단위 위치 탐지

1. Object Detection
이번 글에서는 Object Detection의 개요에 대하여 설명해보고자 한다.
Object Detection이란, 다수의 사물이 존재하는 이미지, 비디오 등에서 각 사물의 위치(bounding box)와 클래스를 찾는 task. (여기서 Bounding box란 위 그림의 빨간 박스로 ${x_0,y_0,x_1,y_1}$ 좌표를 의미한다.)

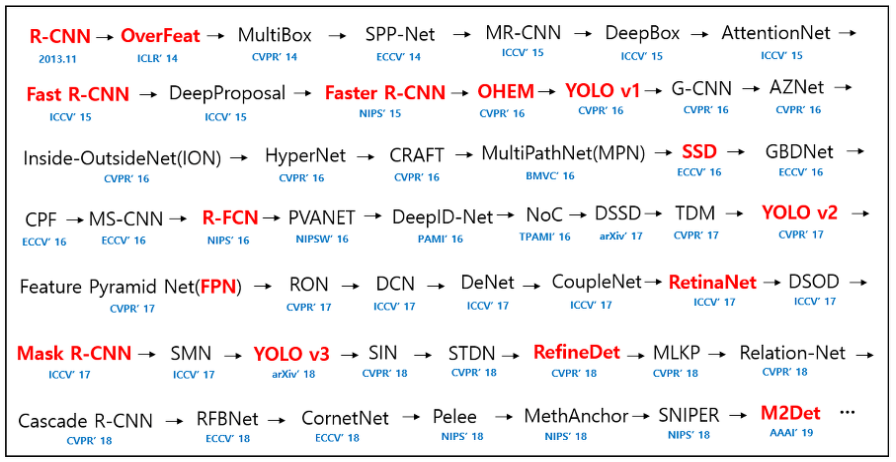
Object Detection 모델들은 위와 같이 다양하게 발전해왔다. 각각 모델들을 특징에 대하여만 간략하게 알고 넘어가자.
1 stage Detector: YOLO, SSD
- 물체의 위치를 찾는 localization과 classification을 한 번에 해결하는 방식
- 2 stage 방식보다 빠르지만, 정확도가 떨어진다.
2 stage Detector: R-CNN, Fast R-CNN, Faster R-CNN
- 물체의 위치를 찾는 localization과 classifiaction을 순차적으로 해결하려는 방식
- 물체의 위치를 먼저 추정하고( region proposal), 각 클래스를 분류
→ bounding box를 통해서 물체의 위치 추정
2. Region Proposal (물체 위치 찾기)
2-1.Sliding window
- 이미지에서 다양한 형태의 window를 슬라이딩하며 물체가 존재하는지 확인
- 너무 많은 영역에 대하여 확인해야 한다는 단점
- feature map이 아니라 입력 이미지에 대해서 cpu 장치를 이용해 sliding window를 진행하게 되면 넓은 input space 상에서 모두 탐색하게 되어 느릴 수 있다는 단점이 있다

2-2. Selectvie Search: R-CNN, Fast R-CNN
인접한 영역(region) 끼리 유사성을 측정해 큰 영역으로 차례대로 통합.(픽셀을 통해 유사한 것끼리 점점 합침)
1. 초기 sub-segmentation을 수행한다.
각각의 객체가 1개의 영역에 할당이 될 수 있도록 많은 초기 영역을 생성한다.

2. 작은 영역을 반복적으로 큰 영역으로 통합한다.
Greedy 알고리즘을 사용하여 여러 영역으로부터 가장 비슷한 영역을 고르고 이것들을 좀 더 큰 영역으로 통합을 하며, 이 과정을 1개의 영역이 남을 때까지 반복
초기의 복잡한 영역들을 유사도에 따라 점점 통합.

3. 통합된 영역들을 바탕으로 후보 영역을 만들어낸다.

3. Object Detection 정확도 측정
3-1. 성능평가 지표(Precision & Recall)

1. Precision : 올바르게 탐지한 물체의 수(TP) / 모델이 탐지한 물체의 개수(TP+FP) = TP/(TP+FP)
2. Recall : 올바르게 탐지한 물체의 수(TP) / 실제 정답 물체의 수(TP+FN) = TP/(TP+FN)
모델의 성능을 측정하기 위해 Precision과 Recall을 모두 고려하는 Average Precision(AP) 값을 사용한다.
일반적으로 Precision과 Recall은 반비례 관계를 가지기 때문에 Recall에 따른 Precision값을 고려하기 위하여 Average Precision으로 측정.
이는 모델의 Confidence값에 따라서 평균을 구한다. 이 때, Confidence 값이 높아지면 Precision은 높아짐을 기억해야 한다.
아래의 단조 감소 그래프로 표현하고 빨간색 영역을 채워 넣고 보라색과 빨간색을 모두 합친 영역의 넓이를 계산 → Average Precision으로 사용.

3-2. IoU: Intersection over Union
IoU란 두 bounding box가 겹치는 비율.
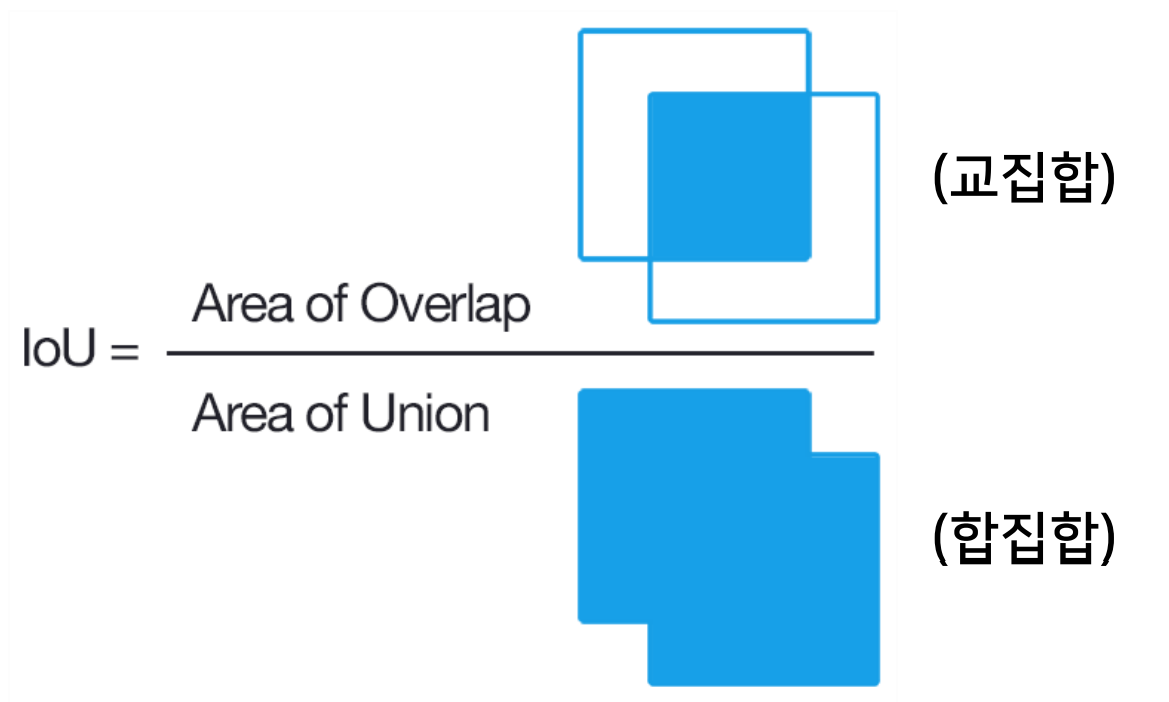

정답 bounding box와 예측한 bounding box의 IOU 비율이 높을수록 정확히 예측한 것으로 판단.
mAP@0.5 = 정답과 예측의 IoU가 50% 이상일 때 정답으로 판정하겠다는 의미
NMS = 같은 class 끼리 IoU가 50% 이상일 때 낮은 confidence box를 제거하여 중복된 box를 지우는 것이다.
3-2-1. NMS(Non-Max Suppression)


NMS란, 여러 개의 바운딩 박스들 중 객체의 Confidence Score가 가장 높은 박스를 선정하고 이 Score보다 낮은 박스들은 삭제한다. Score가 가장 높은 박스와 다른 박스들 간의 IoU를 계산하고 미리 지정한 IoU 임곗값 보다 큰 다른 박스들을 모두 제거한다.

3-3. Confidence Score

Confidence Score란, 특정 바운딩 박스 안에 있는 객체가 어떤 물체의 클래스일 확률과 IoU값을 곱한 값인데, 위 그림의 예시로 들자면 각 바운딩 박스 안에 자동차가 있을 확률이다.
정리하면,
- Confidence score가 임계값보다 낮은 박스는 제거
- 가장 큰 Confidence score을 가진 박스와 다른 박스들 사이의 iou를 비교하여 임계값 이상이면 제거(==같은 물체를 나타내고 있다는 것을 확인)
4. Bounding Box regression
지역화(localization) 성능을 높이기 위해 사용.

예측 위치는 P(predict)로 bounding box의 중심점 x, y 좌표와 bounding box의 width, height 좌표로 구성.
좌표(x, y, w, h)에 대해서 학습을 진행하면서 linear regression으로 좌표의 위치를 조정 및 예측.
5. Dataset
Object Detection에 자주 사용되는 Dateset에 대하여 알아보자 .
5-1. COCO: Common objects in context
COCO - Common Objects in Context
cocodataset.org

- 91개의 class로 이루어진 사물 및 동물 모음
- 최대 640 x 480 RGB 이미지
- 330K 이미지 데이터
- 총 1.5M개의 사물이 annotation 되어 있음.
.
5-2. Pascal VOC
The PASCAL Visual Object Classes Homepage
2006 10 classes: bicycle, bus, car, cat, cow, dog, horse, motorbike, person, sheep. Train/validation/test: 2618 images containing 4754 annotated objects. Images from flickr and from Microsoft Research Cambridge (MSRC) dataset The MSRC images were easier th
host.robots.ox.ac.uk

- 20개의 class로 이루어진 사물 및 동물 모음
- 500 x 375 RGB 이미지
- 11K 이미지 데이터
- 27K개의 사물이 annotation 되어 있음
'ML & DL > Computer vision' 카테고리의 다른 글
| YOLO: You Only Look Once (0) | 2023.10.26 |
|---|---|
| SSD(Single Shot MultiBox Detector) (0) | 2023.10.26 |
| R-CNN, Fast R-CNN, Faster R-CNN (0) | 2023.10.26 |
| NAS(Neural Architecture Search) (0) | 2023.10.26 |
| ResNet (0) | 2023.10.26 |