
semantic segmentation을 해결하기 위해 다양한 방법론이 나왔는데, deeplab시리지는 여러 모델중 상위권에 속한다.
- DeepLab V1 : Atrous convolution을 처음 적용
- DeepLab V2 : multi-scale context를 적용하기 위한 Atrous Spatial Pyramid Pooling (ASPP) 기법을 제안
- DeepLab V3 : 기존 ResNet 구조에 Atrous Convolution을 활용해 좀 더 Dense한 feature map을 얻는 방법을 제안
- DeepLab V3+ : Depthwise Separable Convolution과 Atrous Convolution을 결합한 Atrous Separable Convolution의 활용을 제안
그 중 마지막에 나온 deeplabv3+는 2018년에 구글에서 나와 나온지 오래되었지만, 아직도 높은 성능을 기록하고 있고, 3개의 주요 특징을 갖고있음
ㆍASPP(Atrous Spatial Pyramid Pooling)
ㆍencoder-decoder structure
ㆍdepthwise separable convolution
1. ASPP(Atrous Spatial Pyramid Pooling)
기본적으로 ASPP를 사용하기 때문에 하나의 이미지를 다양한 크기의 조각에서 바라볼 수 있게 되므로, 비교적 풍부한 문맥적인 정보를 추출할 수 있다.



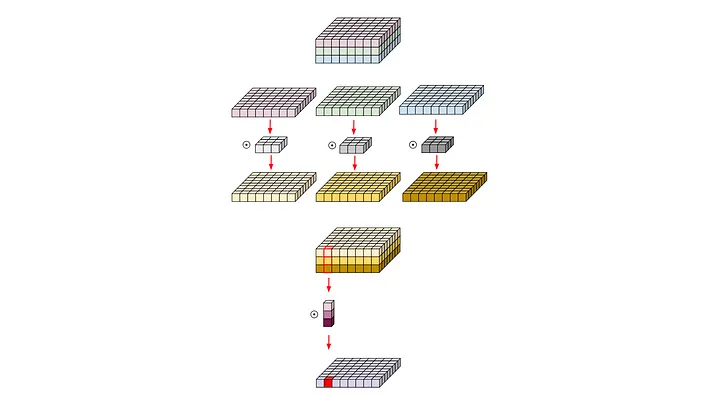
Atrous에서 trous는 구멍(hole)을 의미함으로써, Atrous Convolution은 기존 Convolution과 다르게 필터 내부에 빈 공간을 둔 채 작동하게 된다. 위 그림에서 얼마나 빈 공간을 둘지 결정하는 파라미터값 r(rate의 약자)이 1인 경우, 기존 Convolution과 동일하고 r이 커질수록 빈 공간이 넓어지게 되는 것이다.
이러한 Atrous Convolution을 활용함으로써 얻을 수 있는 이점은 기존 convolution과 동일한 양의 파라미터와 계산량을 유지하면서도, field of view(한 픽셀이 볼 수 있는 영역)를 크게 가져갈 수 있게 된다.
보통 Semantic Segmentation에서 높은 성능을 내기 위해서는 CNN의 마지막에 존재하는 한 픽셀이 입력값에서 어느 크기의 영역에서 커버할 수 있는지를 결정하는 receptive field 크기가 중요하게 작용한다. 즉, 여러 convolution과 pooling 과정에서 디테일한 정보가 줄어들고 특성이 점점 추상화되는 것을 어느정도 방지할 수 있기 때문에 DeepLab series에서는 이를 적극적으로 활용하려 노력한다.
Semantic segmentaion의 성능을 높이기 위한 방법 중 하나로, spatial pyramid pooling 기법이 자주 활용된다.
DeepLab V2에서 feature map으로부터 rate가 다른 Atrous Convolution을 병렬로 적용한 뒤, 이를 다시 합쳐주는 ASPP기법을 활용할 것을 제안했었다.
이러한 이러한 방법들은 multi-scale context를 모델 구조로 구현하여 보다 정확한 Semantic Segmentation을 수행할 수 있도록 도우며, DeepLab V3부터는 ASPP를 기본 모듈로 계속 사용하고 있다.

Depthwise separable convolution은 일반적인 convolution을 두가지 과정을 통해 진행되는데 먼저 depthwise convolution을 진행하고, pointwise convolution(1 x 1 convolution)을 진행한다. 이는 연산 복잡도를 크게 감소시켜준다.
depthwise convolution은 각 채널마다 특정 커널이 존재하고, 이 커널을 통해 해당 channel에 대해서만 convolution을 진행한다. 그 후 pointwise convolution에서는 depthwise convolution의 결과물에 대해서 1 x 1 convolution을 진행한다.
이 논문에서는 Astrous convolution에다 Depthwise separable convolution을 적용시켰고, 이를 astrous separable convolution이라고 부르고 있습니다. astrous separable convolution을 적용 시에 모델의 성능은 비슷하게 유지되고 연산 복잡도는 크게 감소되었다고 한다.
2. encoder-decoder structure
encoder-decoder 구조를 사용하기 때문에 위에서 추출한 정보를 가지고 segmentation을 진행할 시, 물체의 경계가 모호하지 않도록 공간적인 정보를 최대한 유지할 수 있게 된다.
기본적으로 semantic information(=encoder의 output)은 encoding시에 pooling과 striding을 주는 convolution으로 인해 물체 경계와 관련된 정교한 정보들을 잃게 되는데, 그럼 feature map을 더 정교하게 만들면 되지않나라는 물음에는
(논문이 나온 시점에서) 성능이 좋은 neural network의 구조와 한정된 GPU 메모리를 고려했을 때, feature map(encoder의 output)의 크기는 input 사진의 크기보다 8배이상 더 작아야 되어 불가능하다고 한다.

3. depthwise separable convolution
모델의 성능은 유지하면서 계산 비용과 parameter의 개수를 줄일 수 있는 방법 → Xception에서 사용되었음
depthwise separable convolution을 활용하기 때문에 정확도와 속도의 trade-off를 해결하였다.
논문의 저자는 depthwise separable convolution이 성공을 이뤘기 때문에, semantic segmentation에서 사용하기에 적합하고 속도와 정확도 두가지 측면에서 모두 이점을 가지도록 기존 Xception model에 depthwise separable convolution을 적용했다

Reference
DeepLab v3+ 논문 리뷰
논문 제목: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation DeepLab v3+ 개요 Spatial pyramid pooling(SPP)와 encoder-decoder
velog.io
[논문리뷰] DeepLabv3+의 이해
이 글에서는 DeepLabv3+모델 논문인 'Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation' 에 대해 다뤄볼 예정입니다. (링크: https://arxiv.org/pdf/1802.02611.pdf) 이 논문을 읽어본 이유는지난 Sem
cake.tistory.com
[Semantic Segmentation] DeepLab v3+ 원리
논문1. DeepLab V1 : https://arxiv.org/pdf/1412.7062.pdf 논문2. DeepLab V2 : https://arxiv.org/pdf/1606.00915.pdf 논문3. DeepLab V3 : https://arxiv.org/pdf/1706.05587.pdf 논문4. DeepLab V3+ : https://arxiv.org/pdf/1802.02611.pdf 1. Semantic Segmenta
kuklife.tistory.com
'ML & DL > Computer vision' 카테고리의 다른 글
| Contour Detection (0) | 2024.01.29 |
|---|---|
| Morphological Transform (0) | 2024.01.29 |
| U-Net (0) | 2023.10.26 |
| Image segmentation(recognition+localization) (0) | 2023.10.26 |
| EfficientDet (0) | 2023.10.26 |