
1. U-Net
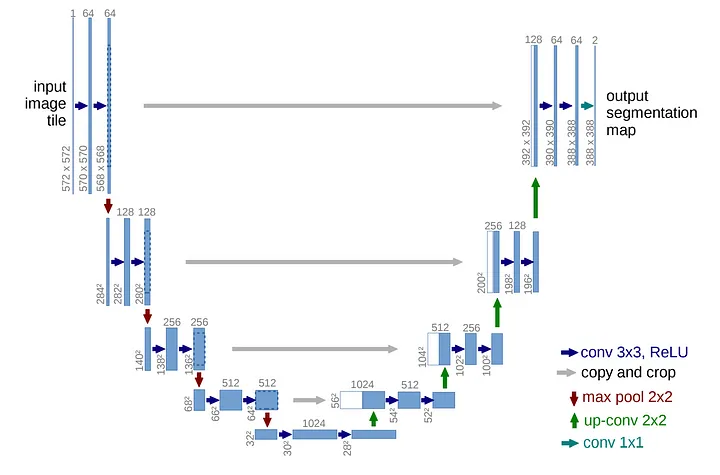
U-net은 본래 의학 이미지 segmentation을 목적으로 나온 모델이다.
의학 이미지 특성상 이미지가 매우 적었고 이러한 매우 적은 수의 학습 데이터로도 정확한 이미지 세그멘테이션 성능을 보여줬다. U-net은 Fully Convolution Network(FCN)을 기반으로 구축하였으며 인코더-디코더 기반의 모델로,
인코딩 단계에서 입력 이미지의 특징을 포착할 수 있도록 채널의 수를 늘리면서 차원을 축소해 나가고,
디코딩 단계에서 저 차원으로 인코딩 된 정보를 이용하여 채널의 수를 줄이고 차원을 늘려서 고차원의 이미지를 복원한다.
1-1. Skip connection

일반적인 segmentation 모델의 인코더는 차원 축소를 거치면서 객체에 대한 위치 정보를 잃고, 디코딩 단계에서도 저 차원의 정보를 확장시키는 것이기 때문에 위치정보는 그대로 손실된다. 그러나 FCN이 등장함에 따라 Encoder(backbone)과 Decoder 간의 정보전달 역할을 해주는 Skip-connection이 등장하게 되었고 이 skip-connection을 통해 Decoder에서 업샘플링된 feature을 동일 해상도의 encoder에서 나온 feature과 합칠 수 있게 되었다.
이때 FCN에서의 Skip-connection과는 다르게 Encoder에서 나온 feature map과 Deocoder에서 업샘플링된 feature map을 단순 더하는 게 아니라 차원을 늘리는 방향으로 concat 해준다는 것이 특징이다.
1-2. Encoder


인코더와 디코더 모두에서 3x3 컨볼루션을 사용하며, 맨 처음 Input 이미지의 형태는 512*512*3이다.
반복되는 파란색 블록은 위와 같이 converlution layer, Batch normalization, relu가 반복적으로 구성된다.

또한 conv Block을 감싸는 보라색은 인코더블록을 의미하며, 빨간색 선은 2x2 max pooling을 하며 다운 샘플링을 한 후 인코더의 다음 단계로 내보내고, 초록색선은 디코더로 복사하기 위한 skip connection을 나타낸다.(전체 그림을 보는 게 이해가 잘 갑니다) 이 Downsampling 과정에서 convolution layer을 거칠 때 패딩을 주지 않아 이미지의 크기가 작아진다.
1-3. Decoder

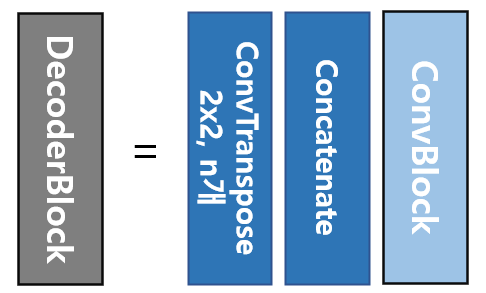
다음으로 디코더 블록의 파란색은 인코더의 convBlock과 동일하며, 녹색블록은 skip connection을 통해서 인코더에서 각 cov layer에서 추출된 featuremap을 복사한 것이다.
노란색 박스는 upsampling을 통해서 차원을 늘리고 채널의 수를 반으로 줄인 것이다. 이 초록색과 노란색 박스를 concatenation 하여 저 차원의 이미지를 확장하며 위치정보를 잃지 않는다. 이들을 모은 회색 블록을 디코더 블록이라고 한다.
마지막으로 디코더의 우측 상단의 출력 부분은 FCN에서와 동일하게 Fc layer을 사용하지 않고 1x1 컨볼루션으로 특징맵을 처리하며 입력이미지의 각 픽셀을 분류하는 segmentation을 수행한다. 컨볼루션 필터의 개수는 분류할 클래스 개수이며, sigmoid 혹은 softmax를 사용하게 된다.



2. 학습 방법
본 논문에서 다양한 학습 장치들을 통해 모델의 성능을 향상했다.
- Overlap-tile strategy : 큰 이미지를 겹치는 부분이 있도록 일정 크기로 나누고 모델의 Input으로 활용.
- Mirroring Extrapolate : 이미지의 경계(Border) 부분을 거울이 반사된 것처럼 확장하여 Input으로 활용.
- Weight Loss : 모델이 객체 간 경계를 구분할 수 있도록 Weight Loss를 구성하고 학습.
- Data Augmentation : 적은 데이터로 모델을 잘 학습할 수 있도록 데이터 증강 방법을 활용.
2-1. Overlap-tile strategy

FCN 구조 상, 마지막에 Fc layer을 사용하지 않기 때문에 입력이미지의 크기에 제한이 없다.
따라서 U-net에서는 이미지의 크기가 큰 경우 이미지를 자른 후, 각 이미지에 해당하는 Segmentation을 진행하는데, U-Net은 Input과 Output의 이미지 크기가 다르기 때문에 위 그림에서 처럼 파란색 영역을 Input으로 넣으면 노란색 영역이 Output으로 추출된다. 동일하게 초록색 영역을 Segmentation 하기 위해서는 빨간색 영역을 모델의 Input으로 사용해야 한다. 즉 겹치는 부분이 존재하도록 이미지를 자르고 Segmentation하기 때문에 Overlap Tile이라고 논문에서는 명칭 한다.
2-2. Mirroring Extrapolate

이미지의 경계 부분을 예측할 때에는 Padding을 넣어 활용하는 경우가 일반적인데 본 논문에서는 이미지 경계에 위치한 이미지를 복사하고 좌우 반전을 통해 Mirror 이미지를 생성한 후 원본 이미지의 주변에 붙여 Input으로 사용한다.
본 논문의 실험분야인 biomedical에서는 세포가 주로 등장하고, 세포는 상하 좌우 대칭구도를 이루는 경우가 많기 때문에 Mirroring 전략을 사용했을 것이라고 추측된다.
2-3. Weight Loss

모델은 위 그림처럼 작은 경계를 분리할 수 있도록 학습되어야 하기 때문에. 논문에서는 각 픽셀이 경계와 얼마나 가까운지에 따른 Weight-Map을 만들고 학습할 때 경계에 가까운 픽셀의 Loss를 Weight-Map에 비례하게 증가시킴으로써 경계를 잘 학습하도록 설계하였다

위 그림은 이미지의 픽셀 위치에 따른 Weight w(x)를 시각화한 것이다. w(x)는 객체의 경계 부분에서 큰 값을 갖는 것을 확인할 수 있다. 객체 간 경계가 전체 픽셀에 차지하는 비중은 매우 작기 때문에 Weight Loss를 이용하지 않을 경우 경계가 잘 학습되지 않아 여러 개의 객체가 한 개의 객체로 표시될 가능성이 높다.
2-4. Data Augmentation
데이터의 양이 적기 때문에 데이터 증강을 통해 모델이 Noise에 강건하도록 학습시켰다.
데이터 증강 방법으로 `Rotation(회전)`, `Shift(이동)`, `Elastic distortion` 등을 사용하였다
Elasic distortion은 연속체에서 어떤 힘이나 시간 흐름으로 인해 변화가 발생하는 경우 이 힘이 제거된 후 변형이 원래처럼 돌아오게 되면 이 변형을 탄성이라고 하는데, 이렇게 탄성이 있는 경우는 같은 물체라 해도 촬영 방법이나 각도 등에 의해서 다른 결과를 가져올 수 있으므로 이럴 때 사용하면 좋다고 하나 이 외의 경우에도 사용 (사람의 글씨체 차이에 따른 MNIST 적용 등에도 사용했었음)


3. Reference
U-Net 정리
이 포스팅은 대회 준비를 위해 공부한 내용을 정리한 것입니다. 참고자료의 내용을 노트 정리하듯 정리한 것이라 글을 그대로 갖다 쓰는 부분이 있을 수 있습니다.
velog.io
U-Net 논문 리뷰 — U-Net: Convolutional Networks for Biomedical Image Segmentation
딥러닝 기반 OCR 스터디 — U-Net 논문 리뷰
medium.com
[U-Net] U-Net 구조
이미지 세그멘테이션(image segmentation)은 이미지의 모든 픽셀이 어떤 카테고리(예를 들면 자동차, 사람, 도로 등)에 속하는지 분류하는 것을 말한다. 이미지 전체에 대해 단일 카테고리를 예측하는
pasus.tistory.com
'ML & DL > Computer vision' 카테고리의 다른 글
| Morphological Transform (0) | 2024.01.29 |
|---|---|
| DeepLabV3plus (0) | 2023.10.26 |
| Image segmentation(recognition+localization) (0) | 2023.10.26 |
| EfficientDet (0) | 2023.10.26 |
| YOLO: You Only Look Once (0) | 2023.10.26 |