
영어의 경우 합성어나 줄임말 등과 같은 예외처리만 되면 띄어쓰기를 기준으로 토큰화를 진행하면 어느 정도 성능을 보장할 수 있다. 그러나 한국어의 경우 조사나 어미 등이 발달되어 있기 때문에 띄어쓰기만으로 단어를 분리하면 의미적인 훼손이 일어날 수 있다. 한국어의 경우 띄어쓰기 단위가 되는 단위를 어절이라고 부르는데, 어절 토큰화와 단어 토큰화가 같지 않기 때문이다. 이는 한국어가 교착어이기 때문에 발생하는 특징이다.
1. 형태소 분석
형태소 분석이란 형태소를 비롯하여 어근, 접두사, 접미사, 품사 등 다양한 언어적 속성의 구조를 파악하는 것을 의미한다.
이는 형태소를 추출, 분리하고 품사를 태깅(PoS) 순서로 진행된다.
만약 일반적인 영어와 같은 전처리 방법(띄어쓰기 단위로 분류)를 이용하면 한국어에서는 같은 의미의 단어가 서로 다른 토큰으로 표현되게 된다. 이는 모델이 이 3개를 다른 단어로 이해하게 될 수도 있다.
따라서 이들을 형태소 분석을 통해 뒤에 붙는 조사들과 분리하여 따로 추출하게 된다면 토큰들을 더 잘 구분할 수 있게 된다.

1-1. 품사태깅(PoS)
단어들은 표기가 같지만, 품사에 따라서 단어의 의미가 달라지기도 한다.(fly-파리, 날다) 따라서 이러한 품사를 알맞게 태깅해 줌으로써 의미를 정의할 수 있다.
2. KoNLPy
한국어 자연어처리를 위한 패키지로는 KoNLPy가 있는데, 이는 여러 종류의 한국어 형태소 분석기를 사용할 수 있게 해 준다. 포함되어 있는 형태소 분석기의 종류는 아래와 같다. 각 형태소 분석기마다 결과가 다르게 나오게 된다.
- Mecab: 일본어용 형태소 분석기를 한국어를 사용할 수 있도록 수정.
- Okt: Open Korean Text의 줄임말로 오픈소스 한국어 분석기로 과거 트위터의 형태소 분석기.
- Komoran: shineware에서 개발한 형태소 분석기
- Kkma: 서울대학교연구실에서 개발한 형태소 분석기
위의 분석기들은 공통적으로 `morphs`라는 형태소 추출, `nouns`=명사 추출, `pos`라는 품사태깅 메서드들을 제공한다.
우선 기본적으로 KoNLPy를 설치하면 진행할 수 있으며, mecab의 경우에는 환경에 따라 추가적인 설치가 필요하다.
구글 colab의 경우는 아래 코드를 실행하면 되고
!pip install konlpy
!bash <(curl -s https://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh)
from konlpy.tag import Mecab로컬에 설치할 경우 mecab을 윈도에 쉽게 설치할 수 있도록 만들어준 '온전 한 닢'의 패키지를 설치하면 konlpy에서 불러오는 mecab과 동일한 것을 사용할 수 있다.
GitHub - koshort/pyeunjeon: (deprecated) 은전한닢 프로젝트와 mecab 기반의 한국어 형태소 분석기의 독립형
(deprecated) 은전한닢 프로젝트와 mecab 기반의 한국어 형태소 분석기의 독립형 python 인터페이스 - GitHub - koshort/pyeunjeon: (deprecated) 은전한닢 프로젝트와 mecab 기반의 한국어 형태소 분석기의 독립형 p
github.com
pip install konlpy
pip install eunjeon
from eunjeon import Mecab
설치가 완료된 이후에는 각각 분석기를 불러와서 사용할 수 있다.
from konlpy.tag import Kkma, Komoran, Okt
from eunjeon import Mecab2-1. morphs 형태소 추출
sentence = '한국어 자연어처리에는 형태소 분석이 필요하다.'
print("[morps] 형태소 추출")
print("-------------------")
print(f"mecab :{Mecab().morphs(sentence)}")
print(f"Okt :{Okt().morphs(sentence)}")
print(f"kkm :{Kkma().morphs(sentence)}")
print(f"komoran :{Komoran().morphs(sentence)}")
2-2. nouns 명사 추출
sentence = '한국어 자연어처리에는 형태소 분석이 필요하다.'
print("[nouns] 명사 추출")
print("-------------------")
print(f"mecab :{Mecab().nouns(sentence)}")
print(f"Okt :{Okt().nouns(sentence)}")
print(f"kkm :{Kkma().nouns(sentence)}")
print(f"komoran :{Komoran().nouns(sentence)}")
2-3. pos 품사 추출
sentence = '한국어 자연어처리에는 형태소 분석이 필요하다.'
print("[pos] 품사 추출")
print("-------------------")
print(f"mecab :{Mecab().pos(sentence)}")
print(f"Okt :{Okt().pos(sentence)}")
print(f"kkm :{Kkma().pos(sentence)}")
print(f"komoran :{Komoran().pos(sentence)}")
2-4. 분석기 비교
sentence = '아빠가가방에들어가신다'
print(f"mecab :{Mecab().pos(sentence)}")
print(f"Okt :{Okt().pos(sentence)}")
print(f"kkm :{Kkma().pos(sentence)}")
print(f"komoran :{Komoran().pos(sentence)}")
각 분석기마다 속도, 분류방법이 따르기 때문에 적절한 실험을 통해사용해 야한다.
그러나 최근에는 서브워드 토큰화를 사용하여 토큰들에 조사나 어미들이 자연스럽게 분리되면서 형태소분석을 사용하는 경우가 적어지고 있다. 형태소 분석 처리 시간 대비 얻을 수 있는 성능의 이점이 크지 않기 때문이다. 또한 대화를 위한 언어 모델을 학습할 때에는 형태소 분석을 사용하지 않는다.
3. 한국어 코퍼스 전처리 실습
3-1. 코퍼스 수집
우선 한국러 코퍼스를 수집해야 하는데, `Newpaper3 k`라는 라이브러리를 이용하여 url만 입력하면 뉴스기사를 크롤링해 주는 라이브러리를 사용하여 수집한다. 매우 다양한 언어를 지원한다.
!pip install newspaper3k이후 뉴스 url을 입력하고 언어를 지정해 준 다음 진행을 하면 제목과 본문 내용을 뽑아낼 수 있다.
그러나 기본적으로 수집된 데이터에는 문장 기호나 의미 없는 단어들이 포함되어 있기 때문에 처리가 필요하다.
우선 이번 실습에서는 더 다양한 의미없는 문장들을 추가한 뒤, 전처리하는 과정을 실습할 것이다.
article.download()
article.parse()
print('title:', article.title)
print('context:', article.text)
additional_info = [
"영상취재 홍길동(hongkildong@chosun.com) 제주방송 임꺽정 홍길동(hongkildong@chosun.com)",
"<h1>중요한 것은 꺾이지 않는 마음</h1> <h3>카타르 월드컵</h3> <b>유행어</b>로 이루어진 문서입니다."
"<br>이 줄은 실제 뉴스에 포함되지 않은 임시 데이터임을 알립니다…<br>",
"Copyright ⓒ JIBS. All rights reserved. 무단 전재 및 재배포 금지.",
"<이 기사는 언론사 에서 문화 섹션 으로 분류 했습 니다.>",
"<br>이 줄은 실제 뉴스에 포함되지 않은 임시 데이터임을 알립니다…<br>",
"#주가 #부동산 #폭락 #환률 #급상승 #중꺾마"
]
context = article.text.split('\n')
context += additional_info
for i, text in enumerate(context):
print(i, text)이렇게 되면 전처리해야 할 대상 corpus는 아래와 같다.

3-2. 정제
우선 학습에 필요하지 않은 데이터를 제거하거나 필터링을 해야 한다.
기본적으로 불용어리스트를 생성한 뒤 불용어에 해당하는 단어들을 제거해 준다.
# 불용어 사전 정의
stopwords = ['이하', '바로', '☞', '※', '…']
# 불용어 제거
def delete_stopwords(context):
preprocessed_text = []
for text in context:
text = [w for w in text.split(' ') if w not in stopwords]
preprocessed_text.append(' '.join(text))
return preprocessed_text
processed_context = delete_stopwords(context)
for i, text in enumerate(processed_context):
print(i, text)이렇게 불용어를 지정해 주고, 원래 corpus의 context에 적용해 주면 아래와 같이 불용어들이 제거되어 있다.

또한 크롤링등을 통해 수집한 데이터에는 html 태그들과 같이 필요 없는 것들이 있기 때문에 이것 또한 제거해줘야 한다.
import re
def delete_html_tag(context):
"""
ex. <h1>뉴스 제목</h1> -> 뉴스 제목
"""
preprcessed_text = []
for text in context:
text = re.sub(r"<[^>]+>\s+(?=<)|<[^>]+>", "", text).strip()
if text:
preprcessed_text.append(text)
return preprcessed_text
processed_context = delete_html_tag(processed_context)
for i, text in enumerate(processed_context):
print(i, text)
3-3. 문장 분리
현재 수집된 corpus에는 한 행에 여러 문장이 있기 때문에 추후 모델에 넣을 학습데이터를 구성하는데 편리하기 위하여 문장을 분리할 것이다. 문장 분리에는 한국어 문장분리기로 유명한 `kss` 라이브러리를 이용할 것이다.
pip install kssimport kss
def sentence_seperator(processed_context):
splited_context = []
for text in processed_context:
text = text.strip()
if text:
splited_text = kss.split_sentences(text)
splited_context.extend(splited_text)
return splited_context
splited_context = sentence_seperator(processed_context)
for i, sent in enumerate(splited_context):
print(i, sent)
비슷한 과정으로, 이메일이나 해시태그도 제거할 수 있다.
다양한 전처리를 진행하게 되면 최종적으로 아래와 같이 정제된 corpus를 얻을 수 있다.

3-4. 정규화
다음으로는 정규화를 진행한다. 위와 같이 정제된 corpus를 대상으로 반복 횟수가 많거나, 띄어쓰기가 안되어있거나 등을 보정해 준다. 정규화 과정에는 `soynlp`라는 라이브러리를 사용한다.
pip install soynlpfrom soynlp.normalizer import *
print(repeat_normalize('ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ', num_repeats=2))
print(repeat_normalize('얔ㅋㅋㅋㅋㅋㅋㅋ 너 ㅋㅋㅋㅋ 지금 뭐하냐 ㅠㅠㅠㅠ', num_repeats=2))위와 같이 반복되는 단어들을 정규화해 주는 함수도 포함되어 있다.
이 외에도 글에 적지 않은, 띄어쓰기 보정, 중복단어 보정 등의 다양한 한국어 라이브러리를 이용하여 정규화할 수 있다.
3-5. 형태소 분석
다음으로 위에서 배운 형태소 분석기 중 mecab을 이용해서 현재 corpus에서 명사, 동사, 형용사만 필터링하는 작업을 진행한다.
# 명사(NN), 동사(V), 형용사(J)의 포함 여부에 따라 문장 필터링
def morph_filter(context):
NN_TAGS = ["NNG", "NNP", "NNB", "NP"]
V_TAGS = ["VV", "VA", "VX", "VCP", "VCN", "XSN", "XSA", "XSV"]
J_TAGS = ["JKS", "J", "JO", "JK", "JKC", "JKG", "JKB", "JKV", "JKQ", "JX", "JC", "JKI", "JKO", "JKM", "ETM"]
preprocessed_text = []
for text in context:
morphs = Mecab().pos(text)
nn_flag = False
v_flag = False
j_flag = False
for morph in morphs:
pos_tags = morph[1].split("+")
for pos_tag in pos_tags:
if not nn_flag and pos_tag in NN_TAGS:
nn_flag = True
if not v_flag and pos_tag in V_TAGS:
v_flag = True
if not j_flag and pos_tag in J_TAGS:
j_flag = True
if nn_flag and v_flag and j_flag:
preprocessed_text.append(text)
break
return preprocessed_text
post_processed_context = morph_filter(normalized_context)
for i, text in enumerate(post_processed_context):
print(i, text)
3-6. 토큰화
사실 아직 토큰화는 배우지 않았지만, 정제작업을 모두 진행하였기 때문에 토큰화도 진행해 볼 것이다.
우선 이전에 hugging face에서 사용하였던 BERT의 tokenizer이 아닌, tensor flow의 tokenizer을 이용한다.
from tensorflow.keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(post_processed_context)
word2idx = tokenizer.word_index
idx2word = {value : key for key, value in word2idx.items()}
encoded = tokenizer.texts_to_sequences(post_processed_context)
vocab_size = len(word2idx) + 1
print(f"단어 사전의 크기 : {vocab_size}")최종적으로 단어사전이 생성되며 각 토큰화된 단어의 단어사전이 생성된 것을 확인할 수 있다.
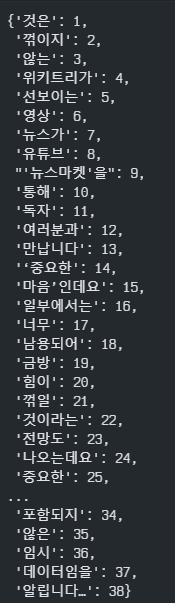
이렇게 한국어 corpus를 수집하고, 다양한 전처리를 진행한 뒤 토큰화까지 진행해 보았다.
다양한 한국어 라이브러리들과 각각의 자연어처리 태스크에 맞게 전처리하는 과정이 매우 중요한 것 같다.
'ML & DL > NLP' 카테고리의 다른 글
| [패캠/NLP] 문장 임베딩 및 유사도 측정 실습 (1) | 2023.12.18 |
|---|---|
| [패캠/NLP] 자연어 특성과 임베딩 (0) | 2023.12.14 |
| 코퍼스 전처리 및 토큰화 (1) | 2023.12.07 |
| [패캠/NLP] HuggingFace 실습 (0) | 2023.11.28 |
| 자연어처리 기초 및 태스크 (2) | 2023.11.27 |