
오늘은 자연어처리를 진행할 때 자주 참고하게 될 hugging face 관련한 실습을 진행하였다.
우선 지금까지 배운내용이 사용되진 않지만 전체적인 flow가 어떻게 되는지 참고할 수 있다.
1. Huggingface
HuggingFace란 자연어처리 모델에서 사용되는 Transformer 기반의 다양한 모델들과 학습 데이터셋들을 모아놓은 플랫폼이다. 또한 pretrained 모델들도 쉽게 사용할 수 있기 때문에 편리하다.
GitHub - huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - GitHub - huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, a...
github.com
Models - Hugging Face
huggingface.co
2. 실습
우선 나의 경우 기본 gpu등을 로컬에 세팅해 뒀기 때문에 colab이 아니라, 로컬에서 실습해보고자 했다.(어차피 나중 가면 colab을 쓰게 될 것 같지만, local이 훨씬 편해서..)
1. 가상환경 생성
우선 `python=3.9.0`의 가상환경을 만들어줬다. (현재 내 세팅은 rtx 3060ti, cuda 11.7, cudnn 8.9.5, pytorch 2.0.0)
--> 원래 cuda 11.2에 pytorch 1.7.1을 사용중이었는데, transformers를 사용하려다 보니 pytorch 2.0.0가 이상이어야 했다. 그래서 막일하면서 다시 설치해 줬다. )
자세한 gpu 세팅법은 아래에 설명되어있다.
딥러닝 GPU cuda 사용하기
1. CUDA 설치 아래 링크에서 본인의 그래픽 카드에 맞는 NVIDIA 드라이버 다운로드. Download the latest official NVIDIA drivers Download the latest official NVIDIA drivers www.nvidia.com 2. CUDA Toolkit 설치 아래 링크에서 하
changsroad.tistory.com
conda install python==3.9.0
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia2. transformer 설치
다음으로 자연어처리 모델들의 기본이 되는 transformers를 설치해 줬다. hugging face에서는 이 transformers 기반의 모델들이 있기 때문에 필수적으로 설치해줘야 한다.
3. BERT 모델 불러오기
이번 실습은 transformer기반의 대표 모델인 BERT를 사용해 볼 것이다.
우선 아래에 automodel로 모델을 손쉽게 불러올 수 있다. model id만 입력하면 자동으로 해당 모델을 불러올 수 있으며, 각 모델 id와 자세한 모델별 상세 페이지는 hugging face에서 참고하면 된다.
from transformers import AutoModel, AutoTokenizer, BertTokenizer
BERT_MODEL_NAME = "bert-base-cased"
bert_model = AutoModel.from_pretrained(BERT_MODEL_NAME)4. Tokenizer 불러오기
BERT 모델을 불러왔다면, 이제 모델이 학습한 TOkenizer까지 불러와야 모델을 사용할 수 있다.
이후 해당 tokenizer에 담겨있는 단어의 사이즈를 확인해 보면 총 28996개의 토큰으로 구성되어 있다는 것을 확인할 수 있었고, 아래와 같은 것들이 있었다.
bert_tokenizer = AutoTokenizer.from_pretrained(BERT_MODEL_NAME)
print(bert_tokenizer.vocab_size)
>> 28996
for i, key in enumerate(bert_tokenizer.get_vocab()):
print(key)
if i > 8:
break
>> token
>> consume
>> trust
>> lakes
>> refrain
>> Rooney
>> Samantha
>> Poznań5. 문장 테스트
이후 불러온 tokenizer을 이용해서 문장이 어떻게 분절되는지 확인할 수 있다.
sample_1 = "welcome to the natural language class"
sample_2 = "welcometothenaturallanguageclass"tokenized_input_text = bert_tokenizer(sample_1, return_tensors="pt")
for key, value in tokenized_input_text.items():
print("{}:\n\t{}".format(key, value))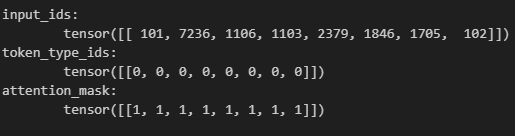
위와 같이 첫 번째 문장을 넣었을 때 토큰 인덱스들이 출력되는 것을 볼 수 있다.
두 번째 문장을 넣었을 때도, tokenizer이 단순 띄어쓰기가 아니라, 단어에 따라 잘 학습되어 1번 결과와 동일한 것을 볼 수 있다.
tokenized_input_text_merged = bert_tokenizer(sample_2, return_tensors="pt")
for key, value in tokenized_input_text.items():
print("{}:\n\t{}".format(key, value))
6. 한국어 문장 테스트
Huggingface에 있는 BERT 모델은 영어 데이터로만 학습한 데이터이기 때문에 영어 이외의 언어가 들어가면 [UNK] 토큰으로 변환된다.
kor_text = "아버지 가방에 들어가신다"
tokenized_text = bert_tokenizer.tokenize(
kor_text,
add_special_tokens=False,
max_length=20,
padding="max_length"
)
print(tokenized_text)
>> ['[UNK]', '[UNK]', '[UNK]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]']따라서 기본 BERT 모델이 아닌, 여러 언어로 학습이 되어있는 다른 모델을 사용해야 한다.
이번 실습에서는 Huggingface에 있는 multi-lingual BERT 모델을 사용해 볼 것이다.
동일한 방법으로 모델과 tokenizer을 불러온다.
MULTI_BERT_MODEL_NAME = "bert-base-multilingual-cased"
multi_bert_model = AutoModel.from_pretrained(MULTI_BERT_MODEL_NAME)
multi_bert_tokenizer = AutoTokenizer.from_pretrained(MULTI_BERT_MODEL_NAME)이 multi-lingaul BERT tokenizer의 vacab size를 보면 기본 BERT는 28996개로 구성되어 있었던 반면 119547로 월등하게 많은 것을 확인할 수 있다.
print(multi_bert_tokenizer.vocab_size)
>> 119547이렇게 불러온 tokenizer로 한국어 문장을 tokenize 해보면, 출력이 되는 것을 볼 수 있다.
kor_text = "아버지 가방에 들어가신다"
tokenized_text = multi_bert_tokenizer.tokenize(
kor_text,
add_special_tokens=False,
max_length=20,
padding="max_length"
)
print(tokenized_text)
>> ['아버지', '가', '##방', '##에', '들어', '##가', '##신', '##다', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]']7. 새로운 토큰 추가
우리가 불러온 모델의 tokenizer에 없는 단어들은 unk라고 뜨는 것을 위에서 확인하였다.
모델의 tokenizer을 불러온 다음 파인튜닝을 위해서 몇 가지 토큰을 추가해보자고 한다.
added_token_num = multi_bert_tokenizer.add_tokens(["한꾺인", "뜰만", "알아뽈", "있꼐", "짝썽하꼤씁니따"])
print(added_token_num)
>> 5
tokenized_text = multi_bert_tokenizer.tokenize(unk_text, add_special_tokens=False)
print(tokenized_text)
>> ['한꾺인', '뜰만', '알아뽈', '쑤', '있꼐', '짝썽하꼤씁니따']
input_ids = multi_bert_tokenizer.encode(unk_text, add_special_tokens=False)
print(input_ids)
>> [119547, 119548, 119549, 9510, 119550, 119551]
decoded_ids = multi_bert_tokenizer.decode(input_ids)
print(decoded_ids)
>> 한꾺인 뜰만 알아뽈 쑤 있꼐 짝썽하꼤씁니따위와 같이 add_tokens를 이용하여 우리가 직접 token을 넣어주면, token이 추가되게 된다.
8. Special token
기존의 tokenizer에는 [BOS], [EOS], [UNK], [SEPT]와 같은 special token들이 있는데, 이것들은 의미를 부가적으로? 설명해 주는 역할을 한다. 이러한 special token도 임의로 생성할 수 있다.
special_token_text = "[DAD]아빠[/DAD]가 방에 들어가신다"
added_token_num = multi_bert_tokenizer.add_special_tokens({"additional_special_tokens":["[DAD]", "[/DAD]"]})
tokenized_text = multi_bert_tokenizer.tokenize(special_token_text, add_special_tokens=False)
print(tokenized_text)
input_ids = multi_bert_tokenizer.encode(special_token_text, add_special_tokens=False)
print(input_ids)
decoded_ids = multi_bert_tokenizer.decode(input_ids)
print(decoded_ids)9. BERT 모델 실습 - [MASK] 토큰 예측
BERT 모델은 MASK 토큰을 예측하는데 학습된 모델로, 비어있는 단어를 예측하는 모델이다.
masked_text = "아빠가 [MASK] 들어가신다"
tokenized_text = multi_bert_tokenizer.tokenize(masked_text)
print(tokenized_text)
>> ['아', '##빠', '##가', '[MASK]', '들어', '##가', '##신', '##다']위와 같이 MASK라는 special token이 추가된 문장이 있다.
이때 transformer의 fill-mask를 우리가 불러온 multi-lingual BERT를 사용해 보면, 아래와 같이 후보들이 나오게 된다.
from transformers import pipeline
nlp_fill = pipeline('fill-mask', model=MULTI_BERT_MODEL_NAME)
nlp_fill(masked_text)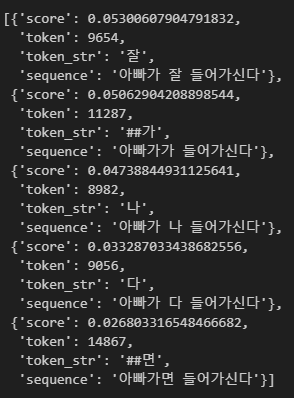
'ML & DL > NLP' 카테고리의 다른 글
| [패캠/NLP] 문장 임베딩 및 유사도 측정 실습 (1) | 2023.12.18 |
|---|---|
| [패캠/NLP] 자연어 특성과 임베딩 (0) | 2023.12.14 |
| 형태소 분석과 전처리 실습 (0) | 2023.12.07 |
| 코퍼스 전처리 및 토큰화 (1) | 2023.12.07 |
| 자연어처리 기초 및 태스크 (2) | 2023.11.27 |