
1. 자연어 Corpus
`자연어 Corpus`=대량의 텍스트 데이터.
--> 자연어처리 작업의 특성을 잘 담아낼 수 있는 다양한 패턴의 데이터가 포함되어야 하며, 유의미한 규모를 가지고 있어야 하고 그 데이터가 대표성을 띄워야 한다.
-> 문제정의 및 설루션을 설정해야 하며 언어 종류, 코퍼스의 종류, 코퍼스의 규모 등을 결정해야 한다.
코퍼스는 외부데이터셋 혹은 온라인 뉴스, 책, 웹 등에서 저작권을 고려하여 수집할 수 있다.
1-1. 코퍼스의 종류
필요한 자연어 코퍼스 유형을 구체적으로 결정해야 한다. 이는 자연어 처리 작업과 연결된다.
이들은 해당 자연어 처리 작업의 특성을 잘 담아낼 수 있도록, 데이터의 패턴이 다양할수록 모델의 일반화 성능이 좋아진다.
ex) 기계번역 작업 = 영어 원본 문장, 한국어 문장 쌍으로 구성된 다량의 데이터가 필요.
한국어 일상대화 챗봇 = 다량의 1:1 한국어 일상대화 데이터
사용자 리뷰 분류 = 사용자 리뷰 데이터와 적절한 레이블
1-2. 코퍼스의 규모
데이터가 많을수록 좋지만, 리소스의 제한이 있기 때문에 어느 정도가 적절한 규모인지 판단해야 함.
이는 자연어처리 작업의 복잡도와 언어 모델의 크기를 고려해야 한다.
또한 모델이 클수록 오버피팅되기 쉽기 때문에 모델이 클수록 더 많은 데이터가 필요.
복잡도 = 패턴의 유형 ex) 이진분류 < 다중분류

1-3. 코퍼스 출처
이미 정제되어 있는 데이터셋을 사용하거나, 직접 데이터를 수집해야 함.
그러나 품질, 저작권, 목적, 데이터의 시점 등 고려해야 할 점이 다양하다. 또한 웹에서 직접 수집할 경우 편향적인 데이터, 가짜 데이터, 정제되지 않은 데이터들을 주의해야 한다.
2. 자연어 데이터 전처리
자연어 코퍼스를 모델에 학습시키기 전 용도에 맞게 정제 및 정규화하는 과정이 필요함.
2-1. 정제
정제(cleaning) 작업이란, 토큰화 작업에 방해가 되는 부분들을 필터링하거나, 토큰화 이후에도 계속적으로 진행되는 전처리 과정. 노이즈란 , 일반적인 노이즈(이상한 단어들)가 있으며 목적에 맞지 않은 데이터들 또한 노이즈라고 정의한다.
일반적으로 불용어 처리, 불필요한 태그 및 특수 문자 제거, 등장 빈도가 적은 데이터 제거 등이 있다.
2-1-1. 불용어(stopword) 처리
불용어란 문장 내에서 빈번하게 발생하나 실질적으로 의미를 가지고있지 않은 용어이다. ex) a, the , is
전체 코퍼스에서 이러한 불용어를 미리 제거해야 시간적이나 단어 사전을 효율적으로 구성할 수 있다.
import nltk
from nltk.corpus import stopwords
# nltk.download() # 처음 한번 실행하여 아래 창에서 전부 다운로드.
eng_stopwords = stopwords.words('english')
print("전체 영어불용어:",len(eng_stopwords))
print(eng_stopwords, end='\n')

위와 같이 nltk 라이브러리에 포함되어 있는 영어 불용어는 179개이며, 이러한 불용어는 tokenizing 할 때 사용하게 된다.
이러한 불용어 사전은 개인이 자연어 처리 태스크에 따라 직접 수정하여 사용한다. (한국어를 지원하지 않는다.)
기본 `word_toknize`는 띄어쓰기 단어로 토크나이징을 진행하였고, 불용어를 제거해 주니 cleaned_tokens에서 볼 수 있듯이 불용어들이 제거된 것을 볼 수 있다.
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
eng_sample= " Back translation is a quality assurance technique that can add clarity to and control over your translated content! "
tokens = word_tokenize(eng_sample)
cleand_tokens = []
for word in tokens:
if word not in eng_stopwords:
cleand_tokens.append(word)
print(tokens)
print(cleand_tokens)
한국어 불용어의 경우 조사나, 접속사 등이 해당되며 분석 결과에 따라 추가적으로 불용어로 취급할 수 있다. 아래 링크에는 보편적인 한국어 불용어들이 정의되어 있다.
Korean Stopwords
ranks.nl
2-1-2. 정규표현식
정규표현식은 특정한 규칙을 가진 문자열의 집합을 표현하는데 사용하는 형식언어로, 복잡한 문자열에서 검색, 치환 등을 하는데 사용된다. 이는 빠르게 코퍼스에서 특정 패턴들을 처리할 수 있어 자주 사용된다.
이는 노이즈를 제거하는 용도로 불필요한 태그나 특수문자 등의 패턴을 지정하여 제거하는 역할을 한다.
그러나 이러한 정제작업을 진행할 때 모두 동일한 과정으로 진행되는 것이 아니라, 현재 자연어 처리 목적에 맞게 분류해야 한다.(@와 같은 기호들은 일반적으로는 불필요할 수 있으나, 이메일 등을 식별해야 하는 작업에서는 필수)

2-2. 정규화
자연어 처리에서 데이터 정규화란 표현방법을 통일시키는 켜 같은 단어로 만드는 것.
이 표 현방법이 다른다는 것은 의미가 같은데 표기가 다른 단어 혹은 품사가 다른 경우 이런 것들이 해당한다.
일반적으로 어간추출, 표제어 추출을 수행한다.
2-2-1. 표제어 추출(lemmatization)
단어들이 다른 형태를 가지더라도, 그 뿌리 단어를 찾아가서 단어의 개수를 줄임. 즉 원형으로 바꾸는 것이다.
ex) am, are, was -> be
from nltk.stem import WordNetLemmatizer
lemmatizer=WordNetLemmatizer()
print(lemmatizer.lemmatize('dies','v'))
print(lemmatizer.lemmatize('watched','v'))
>>die
>>watch2-2-2. 어간 추출(stemming)
형태학적 분석을 단순화한 버전으로 정해진 규칙만 보고 단어의 어미를 자르는 작업.
-> 단순하게 어미를 자르기 때문에 사전에 존재하지 않는 단어가 생성될 수도 있음.
이는 단어의 원래의미를 훼손한다는 단점이 존재함.
2-2-3. 대소문자 통합
이 또한 단어사전의 개수를 줄일 수 있음. 그러나 의미를 구분하기 위한 대문자(나라이름, 사람이름)등의 예외상황을 고려하여 진행해야 함.
2-3. 토큰화
토큰화란 자연어 코퍼스를 최소 의미 단위인 토큰(token)으로 나누는 작업을 말한다. 토큰은 기준에 따라 다를 수 있는데 일반적으로 어절, 단어, 형태소, 음절 등을 의미한다.

토큰화는 자연어 이해능력향상과 자연어를 효율적으로 표현하기 위해 진행된다.
전체 문장을 단어 수준으로 나눔으로써 언어 모델이 텍스트를 단어 수준으로 이해할 수 있으며 이는 많은 양의 텍스트를 이해하는데 도움이 된다.

또한 한국어의 경우 자음 19개와 모음 21개를 활용하여 사실상 무한개의 문장을 표현할 수 있음. 이러한 자연어 코퍼스를 문장 단위로 관리하기는 불가능함. 따라서 글자 수준으로 토큰을 정의하여 40개의 글자로 다양한 문장을 표현할 수 있음.
이러한 중복 등을 제거한 코퍼스 내의 토큰의 집합을 단어사진 vocabulary라고 부른다.
토큰화는 토큰의 단위를 어떻게 정의할지에 따라 방법이 달라지게 된다.
2-3-1. 문장 토큰화
문장 토큰화는 토큰의 기준을 문장으로 지정한다. 보통 문장 부호(.?! )등을 기준으로 잘라내지만, 예외의 경우가 많음.
이러한 문장 단위 토큰화는 다량의 자연어 코퍼스를 이해하기에 적절한 방식이 아님.


2-3-2. 단어 토큰화
단어 토큰화는 토큰의 기준을 단어로 지정한다. 보편적으로 진행되며 특정 구분기호(공백 등)로 텍스트를 나눈다.
-> 그러나 한국어의 경우 교착어(어근과 접사에 의해 단어의 기능이 결정되는 언어)이기 때문에 공백으로 구분하는 것은 좋지 않음.
이러한 단어 토큰화는 새로운 단어가 추가될수록 단어 사전 크기가 계속해서 증가한다는 단점이 있다. 이는 모델이 사전에서 단어를 찾는데 많은 시간이 소요되는 것으로 이어진다.
이것은 OOV문제를 야기하는데, Out of Vocabulary라고 부르며, 학습되지 않은 단어가 모델 예측 시 입력으로 들어오면 모델이 처리할 수가 없어서 에러가 날 수도 있음.-> 이를 방지하기 위하여 이전 hugging face실습에서 배운 UNK라는 Unknown Token을 만들어놨음.

2-3-3. 문자 토큰화
문자토큰화는 문자 단위로 분리하는 것으로, 단어 토큰화의 한계점을 보완하기 위한 방법이다.
이는 단어 사전의 크기를 유지하며 모든 단어를 표현할 수 있으나, 문장 하나를 생성하는데 많은 추론이 필요해지며 이는 모델의 이측 시간이 증가한다는 단점이 있다.

2-3-4. 서브워드 토큰화
이는 단어, 문자 토큰화의 한계점을 해결하기 위한 방법으로, 문자 토큰화의 확장 버전이라 부르기도 한다.
이는 토큰의 단위를 n개의 문자(n-gram)로 정의하고 해당 기준에 따라 텍스트를 분절한다. 이는 한국어에서도 형태소기반으로 분절하는 등 성능을 높일 수 있으며 이러한 서브워드를 만드는 알고리즘으로 BPE(Byte Pair Encoding)이 사용된다.
3. 서브워드 tokenizing
3-1. BPE(Byte Pair Encoding)
BPE는 자연어처리에서 많이 사용되는 서브워드 토큰화를 진행하기 위한 서브워드를 생성하는 알고리즘이다.
기존 토큰화의 단점을 정리하면,
토큰의 단위를 크게 정의하면, 자연어들을 표현하기 위한 단어 사전의 크기가 너무 커지고 또한 OOV 문제에 취약해진다. 반대로 토큰의 단위를 작게 정의하면 한 토큰의 정보량이 너무 작아지거나 모델의 응답 시간이 오래 걸리게 된다.
3-1-1. 서브워드
서브워드(Subword)란 우리가 일반적으로 정의하는 단어보다 더 작은 의미의 단위.
단어는 이러한 서브워드들의 조합으로 구성된다. ex) Birthday= Birth+Day
이러한 서브워드는 oOOV를 완화시킬 수 있음. 기존에 존재하는 서브워드 토큰으로 조합하여 대처 가능
BPE(Byte Pair Encoding)은 단어의 등장 빈도에 따라 서브워드를 구축하는 알고리즘이다.
간단하게 설명하면, 자연어 코퍼스에 있는 모든 단어들을 글자 단위로 분리한 뒤, 등장 빈도에 따라 글자들을 서브워드로 통합시키는 바텀업 방식이다.
기존에 존재하는 토큰화 방식과 서브워드 토큰화 방식을 비교해 보자.
임의의 자연어 코퍼스에서 빈도를 기반으로 단어사전을 구축하였을 때 기존에 존재하는 토큰화방식은 아래와 같이 단어 사전이 생성된다. `{"low":5, "lower":2,"newest":6,"widest":3` 이때 `lowest`같은 단어가 들어오면 기존 토큰화 방식은 OOV문제가 발생한다. 똑같은 상황에서 서브워드 토큰화 방식은 기본 단어 사전을 위와 같은 예시에서 `l,o,w,e,r,n,s,t,i,d,`로 설정하고, 빈도를 기반으로 반복하여 단어 사전을 늘려나간다.




10번으로 반복 횟수를 지정하였을 때 최종 단어사전은 위와같이 정의되고 이때 lowest라는 기존 단어사전에 없던 단어가 들어왔을 때도 low+est로 대응할 수 있게 된다. 이는 알고리즘의 반복 횟수와 밀접하게 연결되기 때문에 적절한 반복 횟수를 정하는 것이 중요하다.
아래 코드는 BPE논문에 설명되어 있는 알고리즘 코드를 수정한 버전이다.
import re, collections
def get_freq(dictionary):
pairs=collections.defaultdict(int)
for word,freq in dictionary.items():
symbols=word.split()
for i in range(len(symbols)-1):
pairs[symbols[i],symbols[i+1]]+=freq
print("현재 pair들의 빈도수: ", dict(pairs))
return pairs
def merge_dictionary(target_pair, input_dict):
output_dict={}
bigram = re.escape(" ".join(target_pair))
p =re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in input_dict:
w_out=p.sub(''.join(target_pair), word)
output_dict[w_out]=input_dict[word]
return output_dict
num_iter=10
dictionary={
' l o w':5,
'l o w e r':2,
'n e w e s t':6,
'w i d e s t':3
}
vocab=['l','o','w','e','r','n','s','t','w','i']
for i in range(num_iter):
print(f"{i+1}번째 BPE")
pairs=get_freq(dictionary)
best=max(pairs,key=pairs.get)
dictionary = merge_dictionary(best, dictionary)
vocab.append("".join(best))
print(f"new merge: {best}")
print(f"dictionary: {dictionary}")
print(f"vocabulary:{vocab}")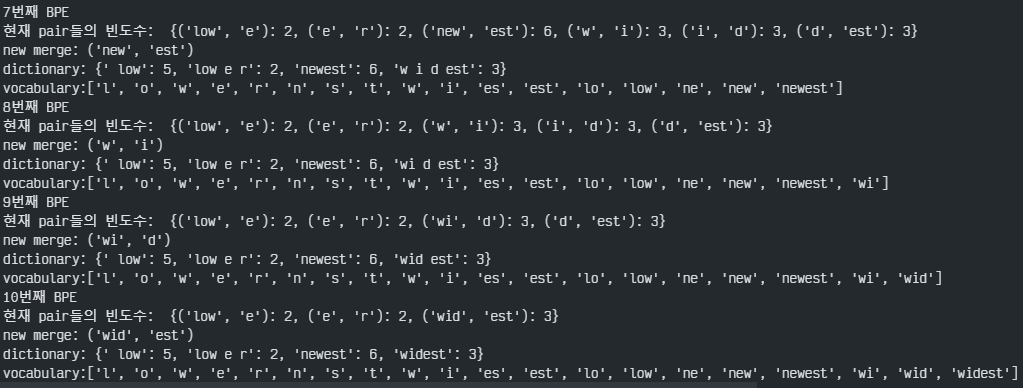
이러한 서브워드 토큰화를 위한 알고리즘에는 BPE 말고도 다른 알고리즘도 있다.
3-2. WordPiece Tokenizer
구글에서 발표한 WordPiece Tokenizer은 단어 사전에 출현 빈도가 높은 쌍이 있을 때 그 각각이 다른 단어 내에서 매우 빈번하게 출현하여 높은 빈도를 나타내면 굳이 병합하지 않고, 각각이 자주 사용되지 않는 다면 더 먼저 병합하는 특징이 있다.->한마디로 빈도에만 신경 쓰지 않음.
GPT모델과 같은 생성모델의 경우 BPE알고리즘을 사용하고 있고, BERT와 ELECTRA와 같은 자연어 이해 모델은 WordPiece Tokenizer을 이용하고 있음.
'ML & DL > NLP' 카테고리의 다른 글
| [패캠/NLP] 문장 임베딩 및 유사도 측정 실습 (1) | 2023.12.18 |
|---|---|
| [패캠/NLP] 자연어 특성과 임베딩 (0) | 2023.12.14 |
| 형태소 분석과 전처리 실습 (0) | 2023.12.07 |
| [패캠/NLP] HuggingFace 실습 (0) | 2023.11.28 |
| 자연어처리 기초 및 태스크 (2) | 2023.11.27 |