
자연어 처리 용어
`자연어`: 프로그래밍 언어와 같이 인공적으로 만든 기계 언어와 대비되는 단어로, 우리가 일상에서 주로 사용하는 언어.
`자연어처리`: 컴퓨터가 인간의 자연어를 읽고 이해할 수 있도록 돕는 인공지능의 한 분야
-> 인간과 기계간의 커뮤니케이션을 개선하는 것이 목표(정보추출, 의미 파악, 자연어 소통)
`자연어처리 활용`: 문서분류, 스팸처리, 검색어 추천, 음성인식, 질의응답, 번역 등 다양한 분야에서 사용됨.
`자연어처리(NLP-Natural Language Processing)` = `자연어이해(NLU-Natural Language Understand)`+`자연어생성(NLG- Natural Language Generation)`
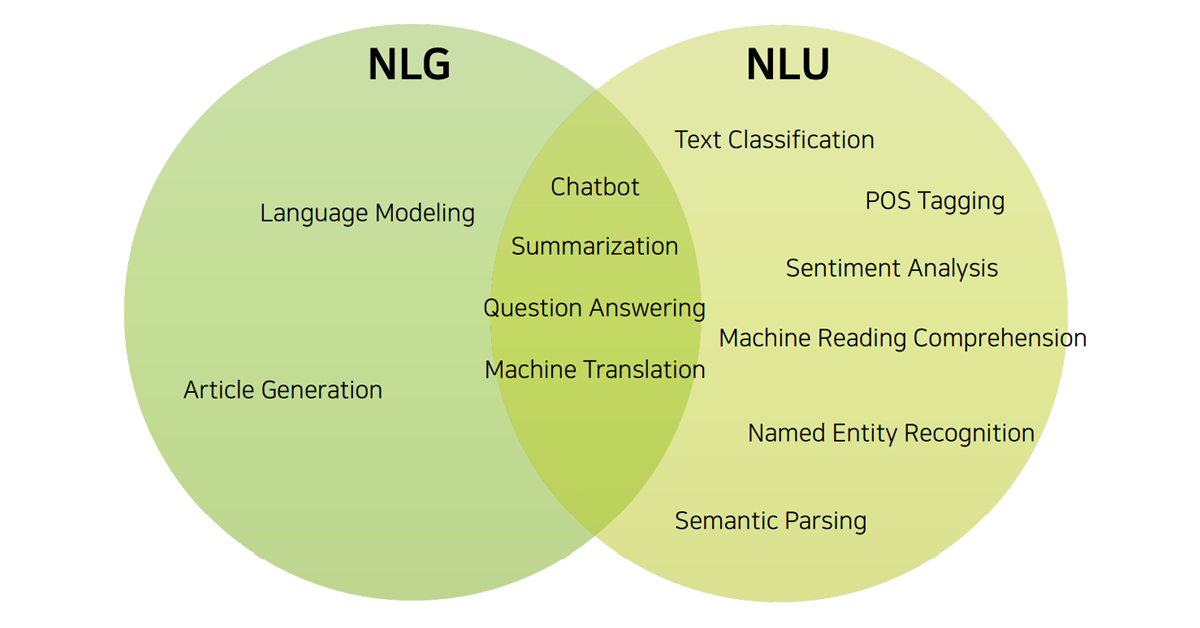
`NLU`: 기계가 자연어의 의미(감정, 의도, 실제 의미, 질문, 비언어적 신호)를 이해하게 되는 것이 목표. 사전처리, 작업이 필요.
`NLG`: 기계가 자연어를 직접 생성하도록 돕는 기술. (최근 모델의 크기, 학습 데이터의 크기가 커져 발전되고 있음.)
1. 자연어처리 TASK
1-1. Text Classification
: 단어, 문장 혹은 문서 단위의 텍스트에 사전 정의된 카테고리를 할당하는 작업( 감정분석, 어뷰징탐색..)

1-2. Information Retrieval and Document Ranking
:우선 두 문서나 문장 간 유사도를 0~1 사이의 숫자로 결정하는 작업에서 시작하여, document DB내의 모든 문서 쌍에 대하여 유사도를 계산하여, 가장 높은 유사도를 가지는 문서를 retrieval 하는 방식으로 작업을 구성.


1-3. Text-to-Text Generation
:텍스트를 입력으로 받아 목표를 달성하는 텍스트를 생성하는 작업. 기계번역, 문서요약, 텍스트 생성 등 다양한 자연어처리 task들이 포함되어 구성.
1. 기계번역
: 소스 언어의 텍스트를 의미를 유지한 채 타깃 언어의 텍스트로 번역하는 작업.
2. 텍스트 요약
: 여러 문서들의 의미를 유지한 채 더 짧은 버전의 텍스트로 요약하는 작업(추출요약과 추상요약으로 나뉨)
추출요약: 문서 내의 중요한문서를 그대로 가져옴.
추상요약: 문서를 이해하고 실제 요약하는 느낌.

3. 텍스트 생성
사람이 작성한 것 같은 텍스트를 생성(앞의 task들도 여기에 포함된다고 볼 수도 있음)

1-4. Knowledge bases, entities and realations
:지식 기반 혹은 의미론적인 엔티니나 관계를 파악하는 자연어처리 분야
1. Named Entitiy Recognition(NER)
: 개체명인식이라고 부르며, 두개의 의미론적인 개체 간의 관계를 식별하는 작업.

2. Relation Extraction
: 텍스트에서 의미론적인 관계를 추출하는 작업 - 주로, 개체 간의 관계를 판별하는 작업으로, 주체와 대상으로 구성.

1-5. Topic and Keywords
: 문서 혹은 문장 내의 주제나 키워드를 파악하는 분야.
1. Keyword Extraction Task
: 주어진 문서 내에서 원하는 키워드를 식별하는 작업. 보통 해당 문서 혹은 문장을 가장 잘 설명하는 대표키워드를 뽑으나, query에 해당하는 단어를 뽑을 수도 있음.

2. Topic Modeling Task
: 문서모음을 추상화하는데 기본이 되는, 주제를 식별하는 작업. 문서 혹은 문장을 가장 잘 추상화할 수 있는 주제를 선택해야 함.

1-6. Chatbot
: 음성이나 문자를 통한 인간과의 대회를 통해서 특정한 작업을 수행하도록 제작된 컴퓨터 프로그램.
정해진 규칙에 맞춰 발화를 출력하는 `규칙기반챗봇`과 문맥을 입력받아 적절한 답변을 생성/검색하는 `인공지능기반챗봇`이 있다.
1-7. Text Reasoning
: 주어진 지식이나 상식을 활용하여 일련의 추론 작업을 수행.
1. Common Sense Reasoning task:
:상식 또는 주어진 지식을 활용하여 추론 작업을 수행.
2. Natural Language Inference task
: 전제와 가설이 주어졌을 때, 가설이 참인지 거짓인지 관련이 없는지 결정하는 작업.
Text-to-Data and vice versa
: 단일 모달인 텍스트 관련 작업 뿐만 아니라, STT 혹은 TTS 그리고 text-to-image 등 다양한 입출력의 모달을 활용가능.
2. 자연어 처리 과정
자연어처리를 수행한다는 것은, 이러한 자연어 처리를 진행하는 모델을 만든다는 것.

2-1. 문제 정의
- 어떤 문제를 풀 것인지에 대하여 정하는 단계
- 자연어 처리 기술 자체는 문제에 대한 설루션이며, 문제정의를 명확히 해야만 정확한 기술을 찾을 수 있음.
2-2. 데이터 수집 및 분석
모델을 사용하기 위한 학습 데이터가 필요함. 이러한 학습 데이터는 다양한 케이스의 데이터가 필요하고, 확률적으로 자주 발생하지 않는 에지 케이스도 포함되어야 함.
데이터 수집
1. Public/ Benchmark Dataset -> 이미 만들어져서 외부에 공개된 데이터 셋을 수집
: 이러한 데이터는 특정 시점에 만들어져 지속적으로 업데이트가 되지 않을 경우, 우리가 정한 문제 상황을 잘 설명하지 못할 확률이 높다. 또한 공개된 데이터셋의 경우 특정 연구 혹은 기술을 타깃으로 수집된 데이터로 일반화된 환경에서는 잘 적용되지 않을 가능성이 높다.
2. Web crawling -> 웹 크롤링을 사용하여 직접 데이터 수집
: 데이터양은 방대하나, 정제되지 않았기 때문에 사전 처리가 필요하며 데이터의 편향이 존재할 가능성이 있기 때문에 사용하기 전 EDA 및 분석 작업을 충분히 수행해야 한다. 또한 원하는 문제에 레이블이 필요하다면 레이블도 붙여줘야 함.
데이터 분석
데이터를 탐색하고 분석하는 과정 EDA라고 하며, 데이터의 분포 및 값을 검토함으로 써 데이터가 표현하는 현상을 더 잘 이해하고, 데이터의 잠재적인 문제를 발견할 수 있음 또한 다양한 패턴을 발견하고 가설을 세울 수 있음.
2-3. 데이터 전처리
- 수집한 데이터의 분석을 진행한 후 전처리 단계에서 잠재적인 문제를 해결. 실제로 자연어처리 진행에서는 데이터 수집 및 전처리 과정의 비중이 매우 높음.
토큰화: 토큰화는 주어진 데이터셋에서 문장이나 문서들을 TOKEN이라고 불리는 단위로 나누는 작업
-> 어절,단어,형태소, 음절 등 단어를 어떤 단위로 살펴볼 것인지 정해야 함.

정제: 갖고있는 데이터셋으로부터 노이즈 데이터(이상치, 편향)를 제거하는 작업
-> 정규표현식이나 불용어 제거등을 이용하여 노이즈 데이터를 제거함
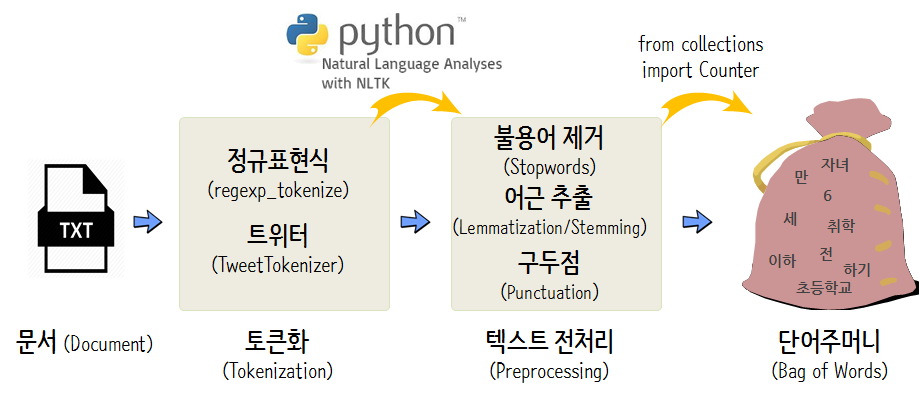
정규화: 표현방법이 다른 데이터들을 통합시켜서 같은 항목으로 합침.
-> 각기 다른 단어형태들을 어간추출(stemming) 혹은 표제어 추출(lemmatization)등을 이용하여 단어들을 통합.
표제어추출은 기본사전형 단어라고 생각하면 됨, 어간 추출에 비해 정확한 어근 단어를 찾아주는데 추출에 있어 시간이 오래 걸린다. 그러나 의미를 알 수 없는 적절치 못한 단어를 추출하기도 한다. (be->am, are, is)
어간추출은 보통 단어들의 어미를 자르는 작업 (formalize->formal)
2-4. 모델링
오늘은 자연어처리의 모델링과 모델 학습 및 평가에 대해서 알아볼 것이다.
자연어 처리의 경우 언어모델(Language Model)을 사용하며, 이는 문장 혹은 단어에 확률을 할당하여 컴퓨터가 처리할 수 있도록 하는 모델.
- 학습 데이터 셋 내 텍스트 기반의 수많은 문장을 통해서 어떤 단어가 어떤 순서로 쓰이는지를 학습하여 추론.

- 작동 원리를 간단한 확률적 표현으로 나타내면, `𝑃(𝑤𝑛|𝑤1, 𝑤2, 𝑤3, … , 𝑤𝑛−1)`로 나타낼 수 있다.
- 문장이란, 어순을 고려하여 여러 단어로 이루어진 단어 시퀀스라고 부르며, n개의 단어로 구성된 단어 시퀀스 w를 확률적으로 표현하면,
` 𝑃(𝑊) = 𝑃(𝑤1, 𝑤2, 𝑤3, … , 𝑤𝑛)`이다.
- 단어 시퀀스 자체의 확률은 모든 단어의 예측이 완료되었을 때, 문장이 완료되어야 알 수 있음.

- 이렇게 특정 문장을 확률로 표현하여, 어떠한 문장이 더 알맞은지를 선정함.

2-5. 모델 학습
- 모델 구조에 따라 학습방법이 다르기 때문에 각기 다른 전처리를 진행해야 함.
- 학습은 대부분 GPU를 이용하여 진행되기 때문에 적절한 환경을 갖추고 진행해야 함.
2-6. 모델 평가
- 학습 전, 후에 평가를 진행하며, 보통 train/valid/test 셋으로 나누고 학습을 진행하며, 학습이 완료된 후에는 적절한 metric 등을 이용하여 학습해야 함.
- 정량평가는 모델의 성능을 정량적으로 평가하는 것으로, 모델의 예측 결과와 실제 정답을 비교함에 따라 모델의 성능을 정량적인 수치로 표현. 이는 채점 기준이 상대적으로 명확한 도메인에서는 신뢰도가 상승. 단 자연어처리의 예측 결과는 text이기 때문에 미묘한 차이에 따라 결괏값이 달라짐.
- 정성평가는 채점에 명확한 기준을 설정할 수는 없으나, 확실한 정답이 정해지지 않은 경우 정성평가를 사용. 이는 실제 사람이 평가하는 방법으로 Human evaluation이라고도 부름. 이는 사람이 평가하기 때문에 미묘한 차이를 구분하여 평가를 할 수 있지만, 사람마다의 편차로 인해 신뢰도를 입증하려면 충분한 평가자가 필요.
'ML & DL > NLP' 카테고리의 다른 글
| [패캠/NLP] 문장 임베딩 및 유사도 측정 실습 (1) | 2023.12.18 |
|---|---|
| [패캠/NLP] 자연어 특성과 임베딩 (0) | 2023.12.14 |
| 형태소 분석과 전처리 실습 (0) | 2023.12.07 |
| 코퍼스 전처리 및 토큰화 (1) | 2023.12.07 |
| [패캠/NLP] HuggingFace 실습 (0) | 2023.11.28 |